2025-02-03
Models
- [ ]
Papers
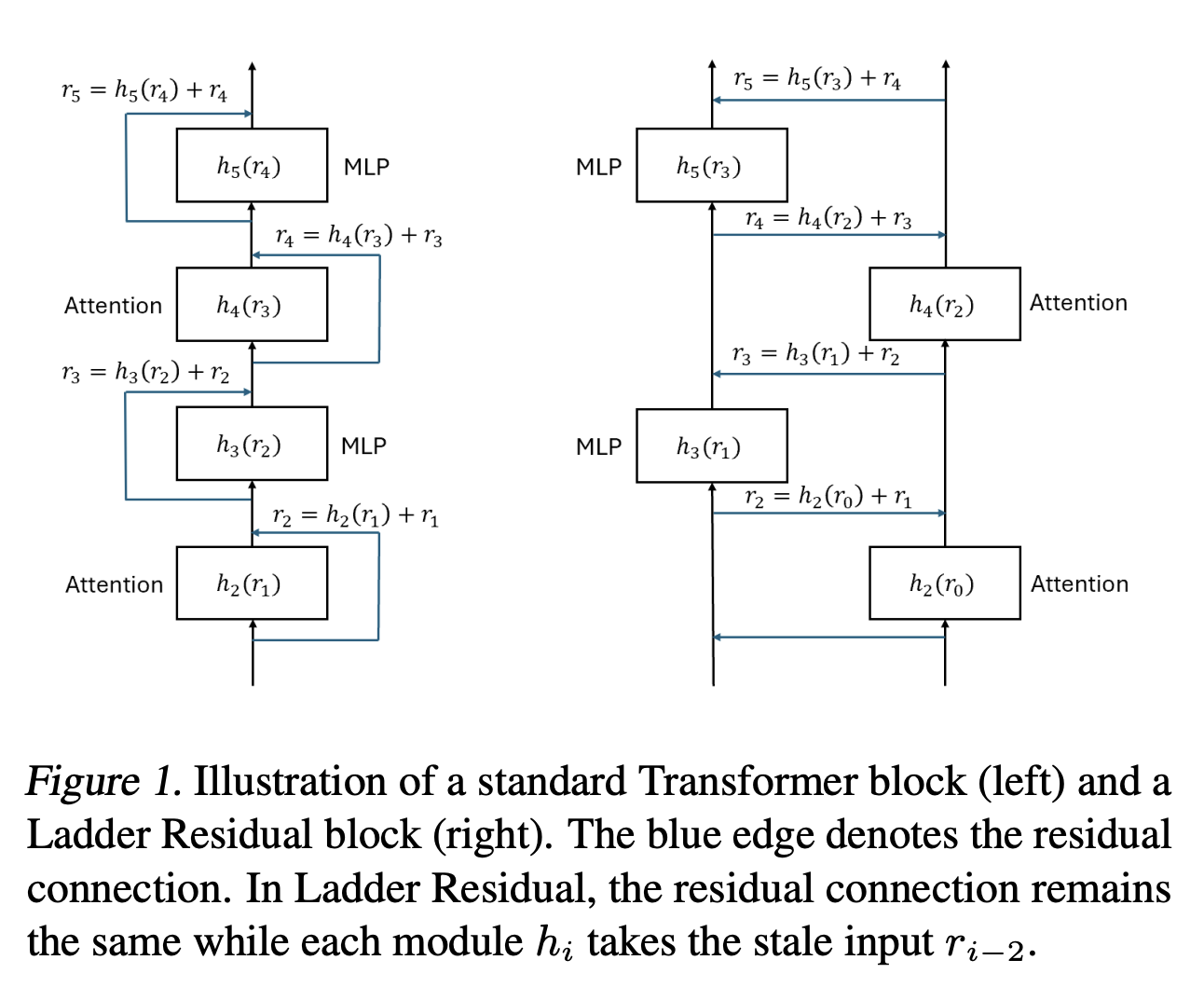
- [2501.06589] Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
- [2410.14874] Improving Vision Transformers by Overlapping Heads in Multi-Head Self-Attention
- [2502.01061] OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
- [2502.01068] FastKV: KV Cache Compression for Fast Long-Context Processing with Token-Selective Propagation](https://arxiv.org/abs/2502.01637)
- [2502.00299] ChunkKV: Semantic-Preserving KV Cache Compression for Efficient Long-Context LLM Inference
- [2502.01637] Scaling Embedding Layers in Language Models
- [2502.01524] Efficiently Integrate Large Language Models with Visual Perception: A Survey from the Training Paradigm Perspective
- [2501.18965] The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training
- [2502.00965] CLIP-UP: A Simple and Efficient Mixture-of-Experts CLIP Training Recipe with Sparse Upcycling
- [2502.01720] Generating Multi-Image Synthetic Data for Text-to-Image Customization
- [2502.02589] COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
- [2502.02538] Flow Q-Learning
- [2502.03444] Masked Autoencoders Are Effective Tokenizers for Diffusion Models
- [2502.02737] SmolLM2: When Smol Goes Big — Data-Centric Training of a Small Language Model
- [2502.03621] DynVFX: Augmenting Real Videos with Dynamic Content
- [2502.01839] Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification
- [2502.03382] High-Fidelity Simultaneous Speech-To-Speech Translation
- [2502.04328] Ola: Pushing the Frontiers of Omni-Modal Language Model with Progressive Modality Alignment
- [2502.04128] Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
- [2502.03128] Metis: A Foundation Speech Generation Model with Masked Generative Pre-training
[2501.06589] Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
[2502.01341] AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
[2502.02492] VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models
Code
Articles
- Home | Let us Flow Together ༄࿐࿔🚀
- How To Scale Your Model
- GRPO with Verifiable (Binary) Rewards Is an Adaptive Weighted Contrastive Loss | Youssef Mroueh
Videos
- [ ]