2024-11-03 - TokenFormer - RETHINKING TRANSFORMER SCAL-ING WITH TOKENIZED MODEL PARAMETERS
- replaces FFN and linear QKV mapping with an attention where keys and values are learned matrices
- allows scaling up the K and V matrices without a need to retrain
-
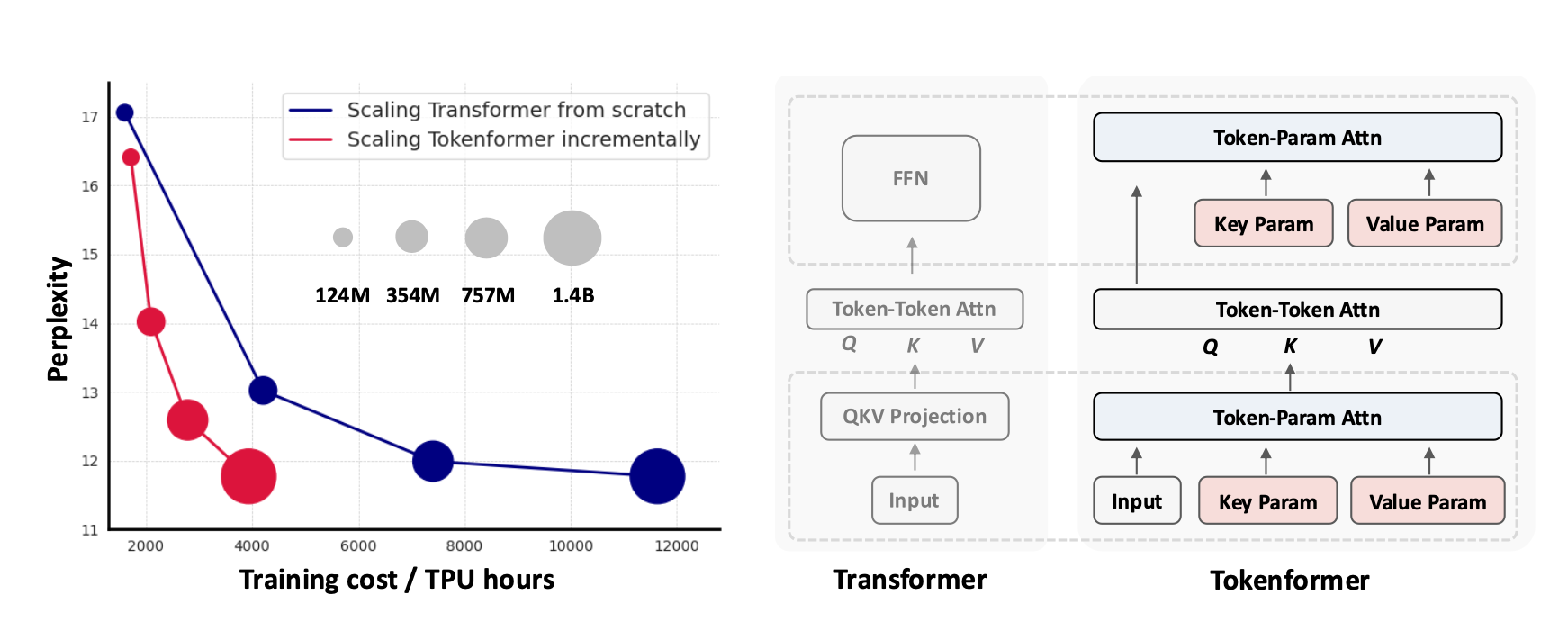
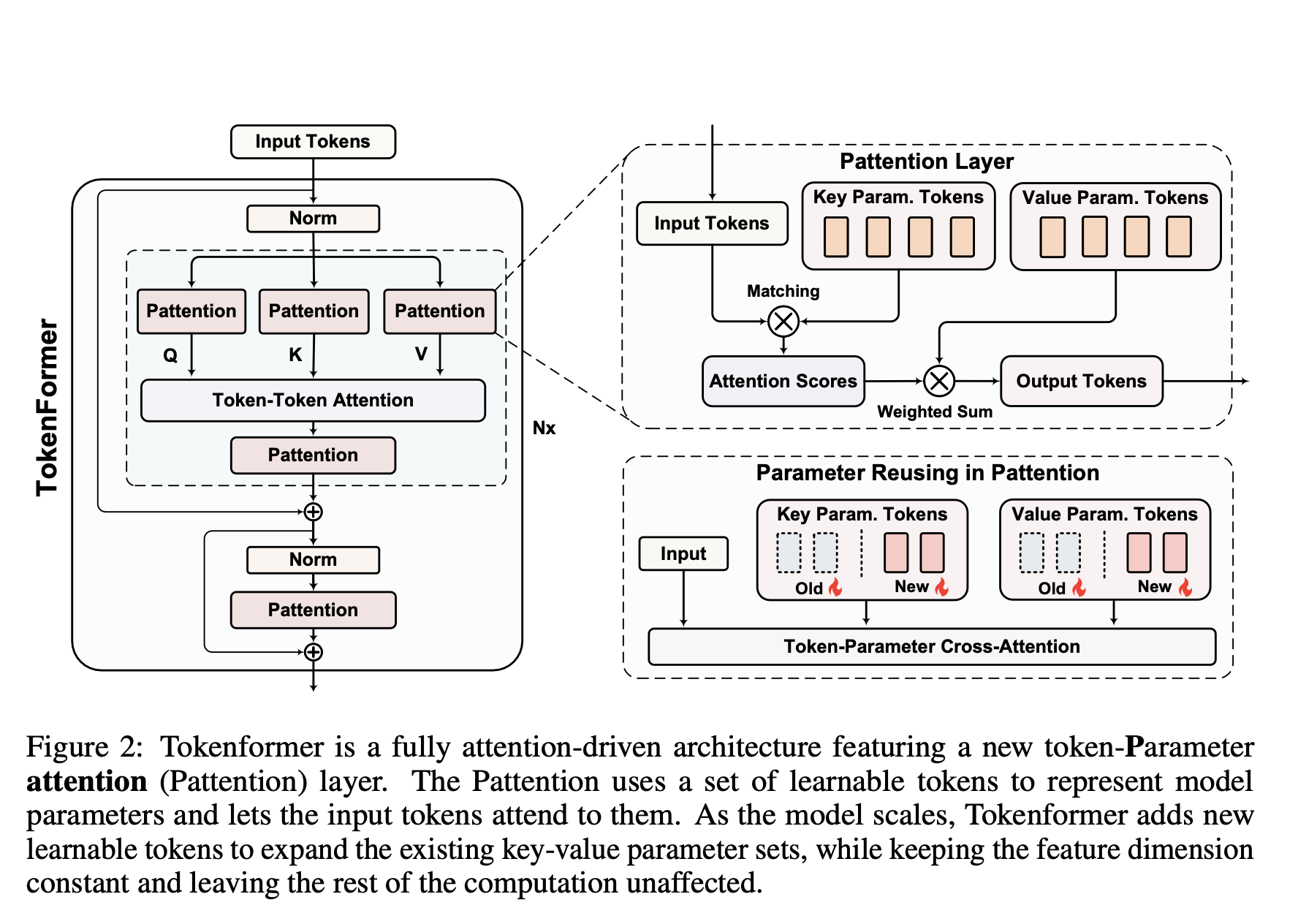

- uses nonparametric layernorm so that only tokens are learned