Long Context Transformers
RoPE Expansion
- Gradient Blog: Scaling Rotational Embeddings for Long-Context Language Models
- rope theta scaling + fine tuning on longer context data
- Extending the RoPE | EleutherAI Blog
YaRN
- GitHub - jquesnelle/yarn: YaRN: Efficient Context Window Extension of Large Language Models
- [2309.00071] YaRN: Efficient Context Window Extension of Large Language Models
Sliding Window Attention
Ring Attention
Tree Attention
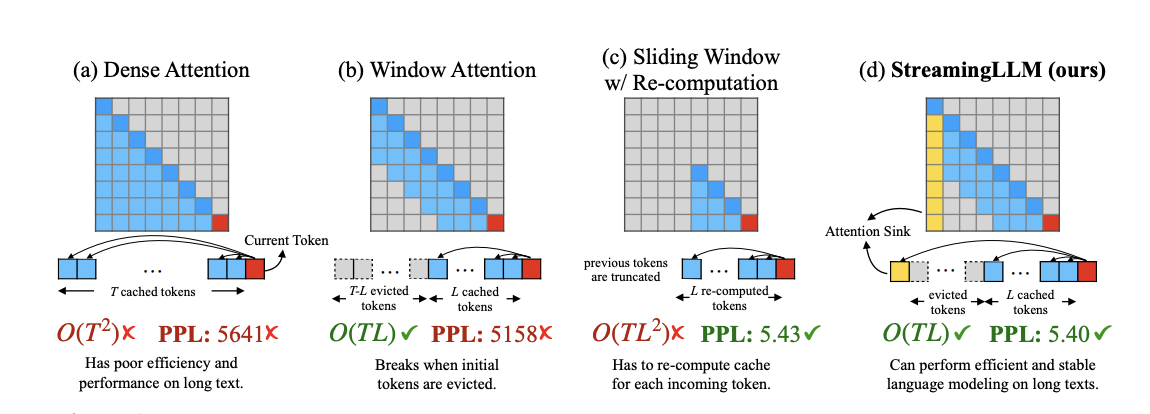
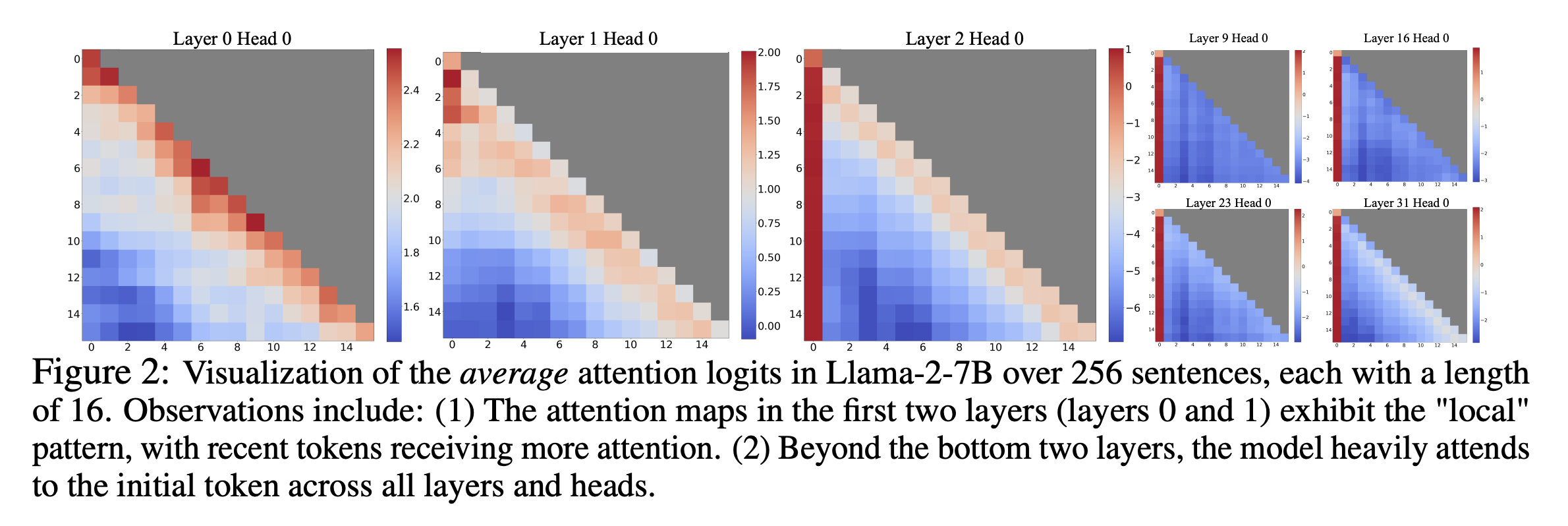
StreamingLLM
- [2309.17453] Efficient Streaming Language Models with Attention Sinks
- StreamingLLM - Efficient Streaming Language Models with Attention Sinks Explained - YouTube
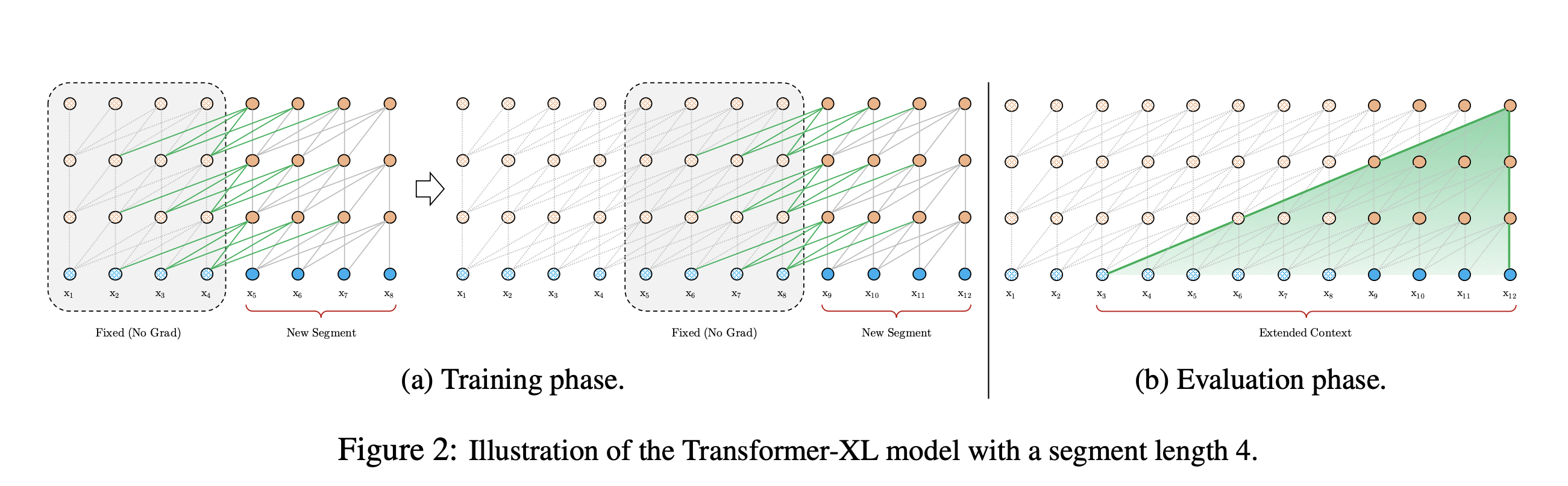
Transformer-XL