Quantization
- GitHub - bitsandbytes-foundation/bitsandbytes: Accessible large language models via k-bit quantization for PyTorch.
- GitHub - pytorch/ao: PyTorch native quantization and sparsity for training and inference
- GitHub - intel/auto-round: Advanced Quantization Algorithm for LLMs. This is official implementation of “Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs”
- GitHub - ChenMnZ/PrefixQuant: An algorithm for static activation quantization of LLMs
- GitHub - vllm-project/llm-compressor: Transformers-compatible library for applying various compression algorithms to LLMs for optimized deployment with vLLM
Training
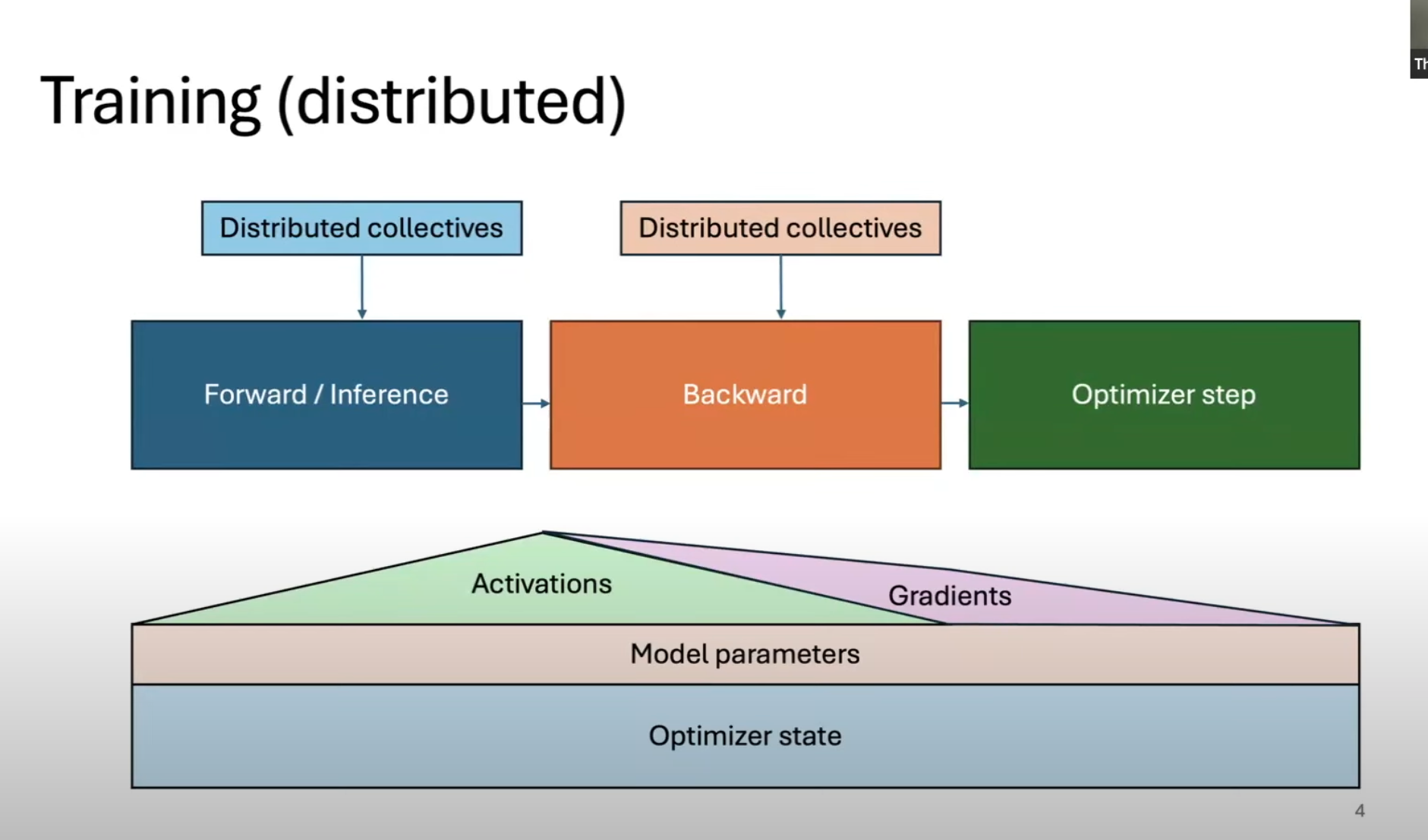
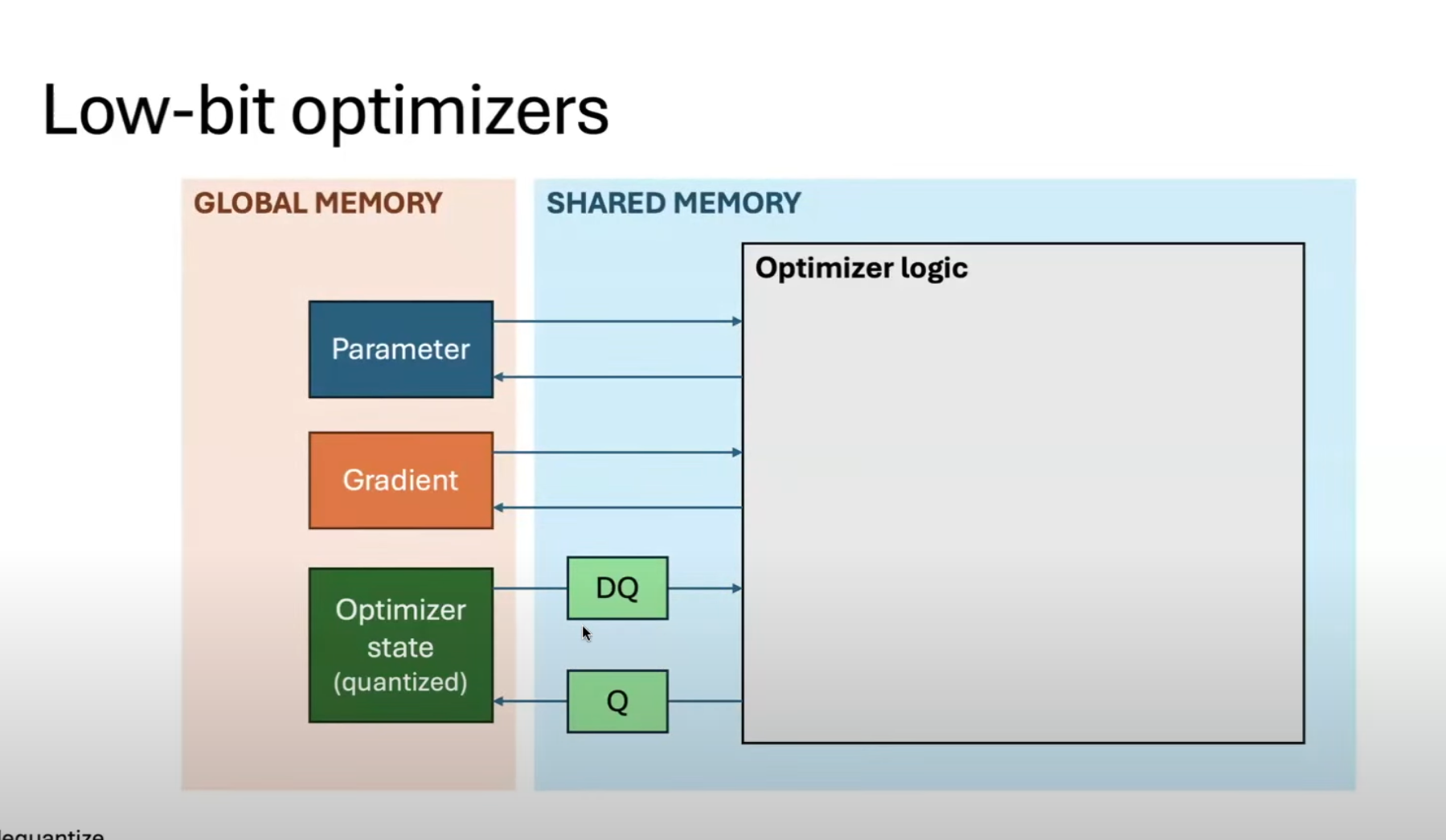


Stochastic Rounding
AutoRound
- 🚀 AutoRound Meets SGLang: Enabling Quantized Model Inference with AutoRound | LMSYS Org
- GitHub - intel/auto-round: Advanced quantization toolkit for LLMs and VLMs. Native support for WOQ, MXFP4, NVFP4, GGUF, Adaptive Bits and seamless integration with Transformers, vLLM, SGLang, and TorchAO