Test Time Compute, LLM Reasoning, Inference Time Scaling
-
Scaling Test Time Compute: How o3-Style Reasoning Works (+ Open Source Implementation) - YouTube
-
o3 (Part 1): Generating data from multiple sampling for self-improvement + Path Ahead - YouTube
-
o3 (Part 2) - Tradeoffs of Heuristics, Tree Search, External Memory, In-built Bias - YouTube
Papers
- [2501.12948] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- [2408.03314] Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- [2410.10630] Thinking LLMs: General Instruction Following with Thought Generation
- [2411.19865] Reverse Thinking Makes LLMs Stronger Reasoners
- [2411.04282] Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding
- [2409.15254] Archon: An Architecture Search Framework for Inference-Time Techniques
- [2410.10630] Thinking LLMs: General Instruction Following with Thought Generation
- [2409.12917] Training Language Models to Self-Correct via Reinforcement Learning
- [2412.18925] HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
- [2412.14135] Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective
- [2412.21187] Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
- [2501.02497] Test-time Computing: from System-1 Thinking to System-2 Thinking
- [2501.04682] Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Though
- [2501.04519] rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
- [2501.09891] Evolving Deeper LLM Thinking
- [2501.19393] s1: Simple test-time scaling
- [2502.01839] Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification
Image Generation
Open Source
-
🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! | DeepSeek API Docs
-
Scaling test-time compute - a Hugging Face Space by HuggingFaceH4
-
GitHub - NovaSky-AI/SkyThought: Sky-T1: Train your own O1 preview model within $450
-
GitHub - Jiayi-Pan/TinyZero: Clean, accessible reproduction of DeepSeek R1-Zero
-
GitHub - volcengine/verl: veRL: Volcano Engine Reinforcement Learning for LLM
-
GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
Reasoning Distillation
Related
Reasoning Datasets
- ServiceNow-AI/R1-Distill-SFT · Datasets at Hugging Face
- open-thoughts/OpenThoughts-114k · Datasets at Hugging Face
- cognitivecomputations/dolphin-r1 · Datasets at Hugging Face
Research
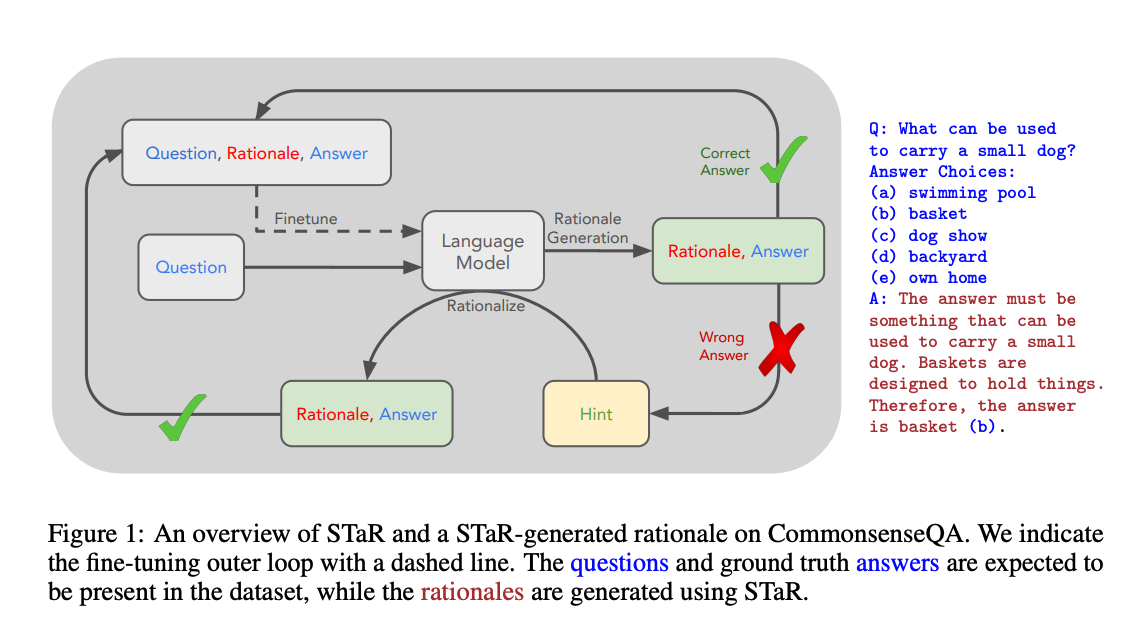
STaR
We propose a technique to iteratively leverage a small number of rationale examples and a large dataset without rationales, to bootstrap the ability to perform successively more complex reasoning. This technique, the “Self-Taught Reasoner” (STaR), relies on a simple loop: generate rationales to answer many questions, prompted with a few rationale examples; if the generated answers are wrong, try again to generate a rationale given the correct answer; fine-tune on all the rationales that ultimately yielded correct answers; repeat. We show that STaR significantly improves performance on multiple datasets compared to a model fine-tuned to directly predict final answers, and performs comparably to fine-tuning a 30× larger state-of-the-art language model on CommensenseQA. Thus, STaR lets a model improve itself by learning from its own generated reasoning.