GPU / CUDA Programming
Programming Massively Parallel Processors (2022)
How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog
Programming Heterogeneous Computing Systems with GPUs and other Accelerators (Fall 2022)
__global__ void kernel(); // define cuda kernel
cudaMalloc((void**)&d, bytes);
cudaMemCpy(dev, host, bytes, cudaMemcpyHostToDevice);
const unsigned int numBlocks = 8;
const unsigned int numThreads = 64;
kernel<<<numBlocks, numThreads>>>(args...);
cudaMemCpy(host, dev);
cudaFree(dev);
// #blocks and #threads
__shared__ // shared memory
__syncthreads();
cudaDeviceSynchronize();
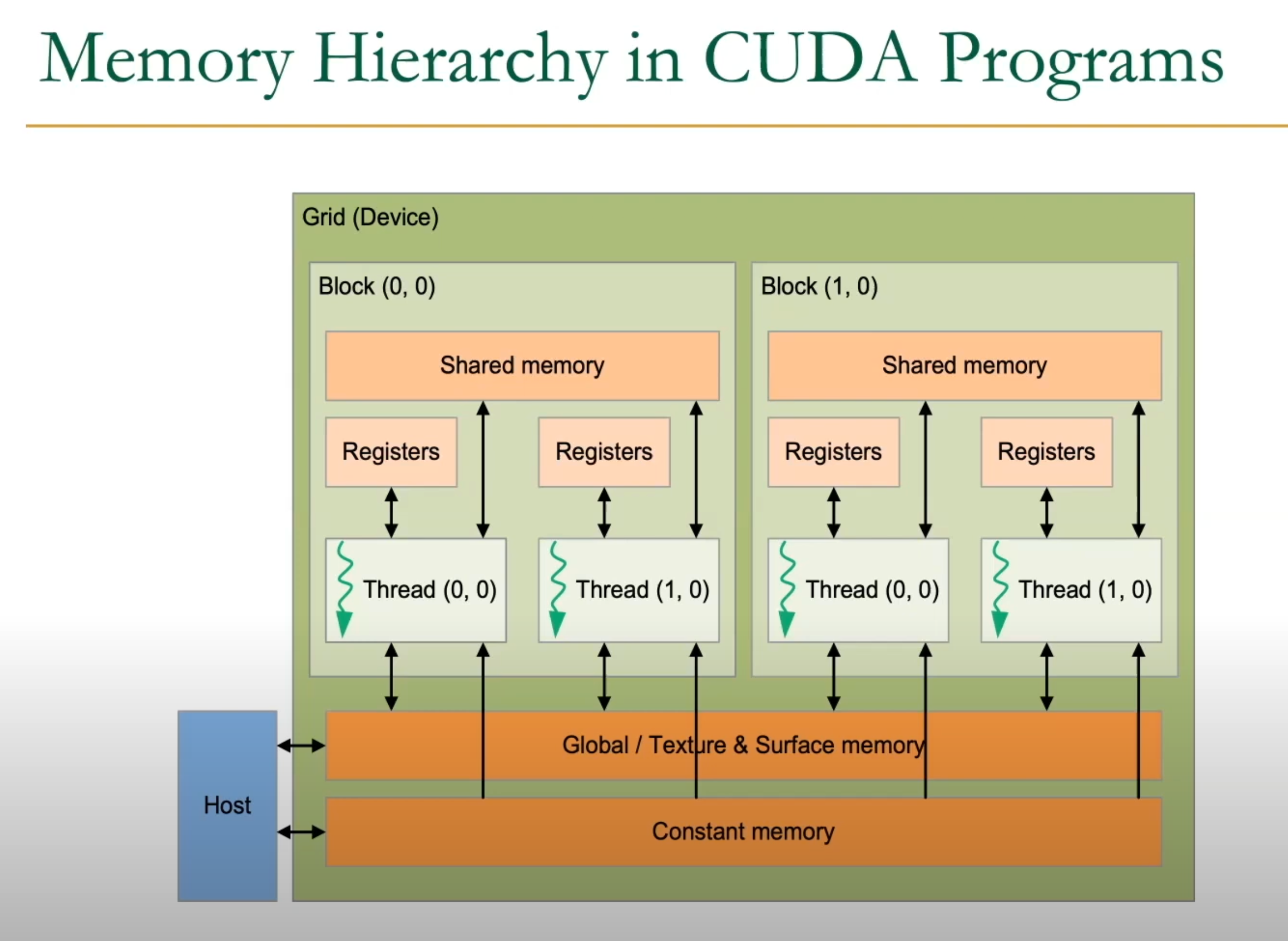
Kernel
__global__ void my_kernel(float* x, float* y) {
int idx = blockDim.x * blockIdx.x + threadIdx.x;
}
2D Blocks
Row major
gridDim.x and gridDim.y
row = blockIdx.y * blockDim.y + threadIdx.y
col = blockIdx.x * blockDim.x + threadIdx.x
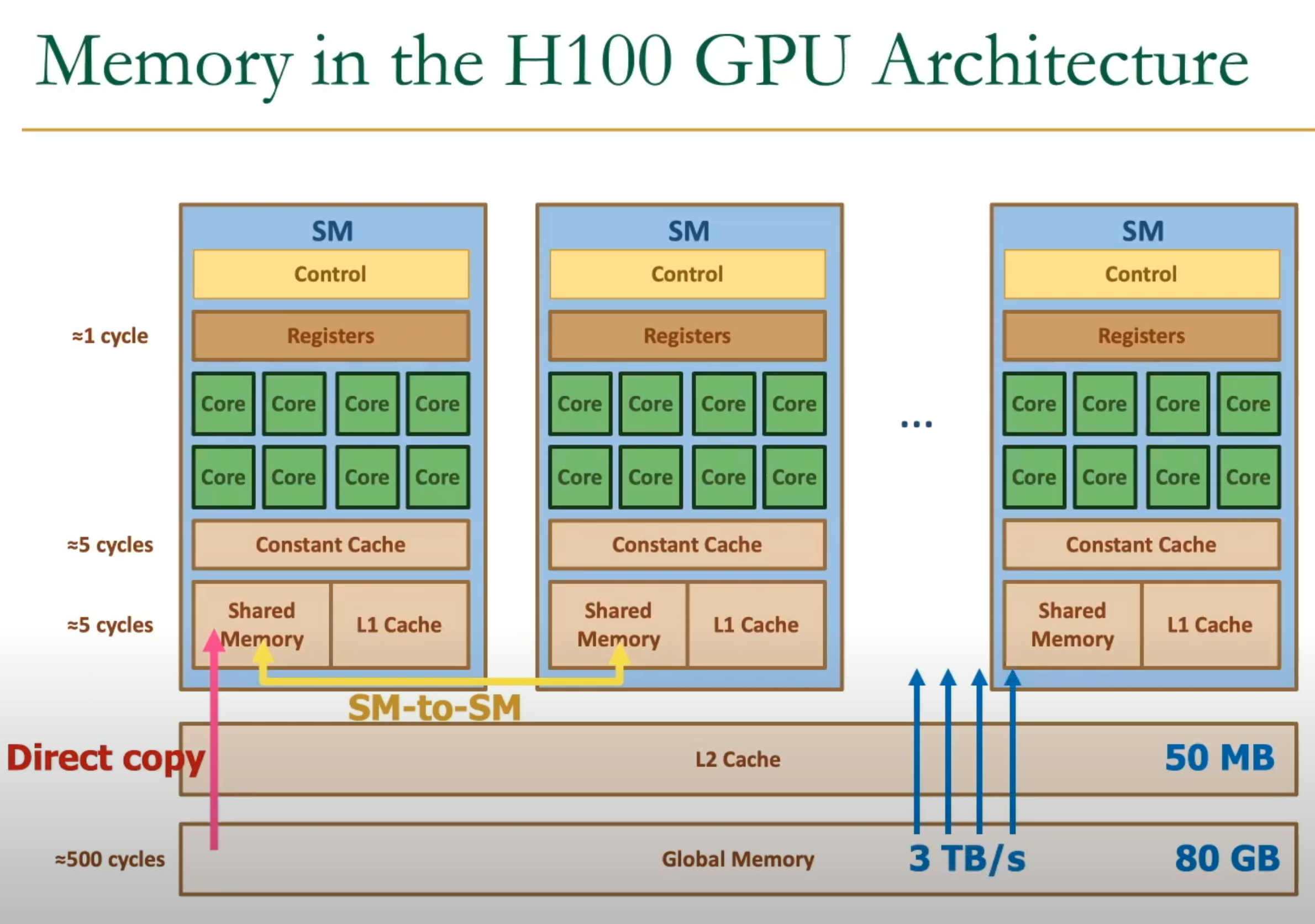
GPU Architecture
HetSys Course: Lecture 4: GPU Memory Hierarchy (Fall 2022)
H100 (Nvidia Hopper Architecture)
NVIDIA Hopper Architecture In-Depth
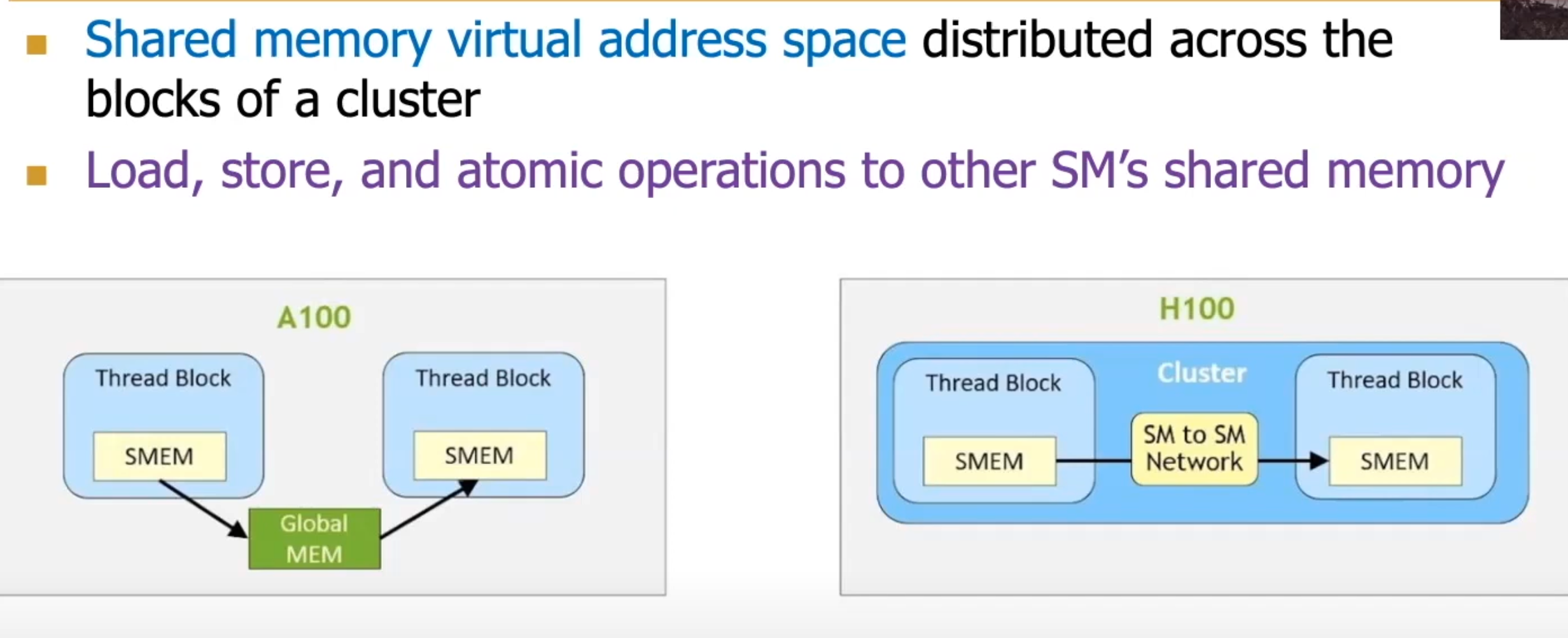
H100 Thread Block Clusters
Thread blocks in the same cluster can sync and exchange data. Makes it possible to avoid having to write intermediate results to global memory
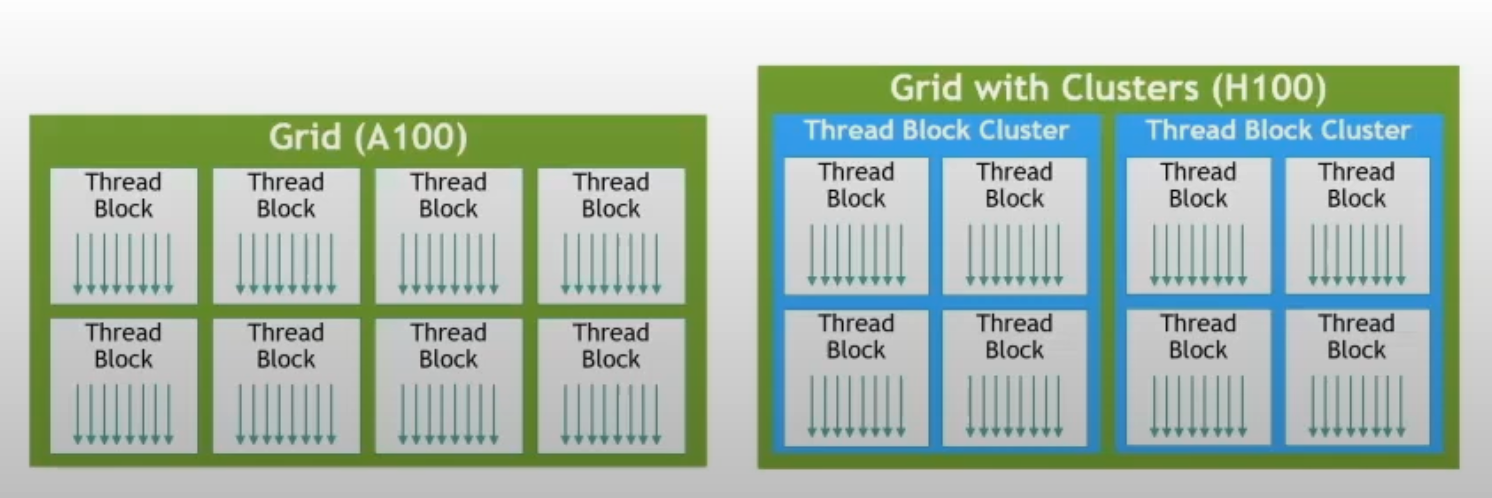
thread < thread block < thread block cluster < grid
GH100: 144 cores, 60MB L2 cache
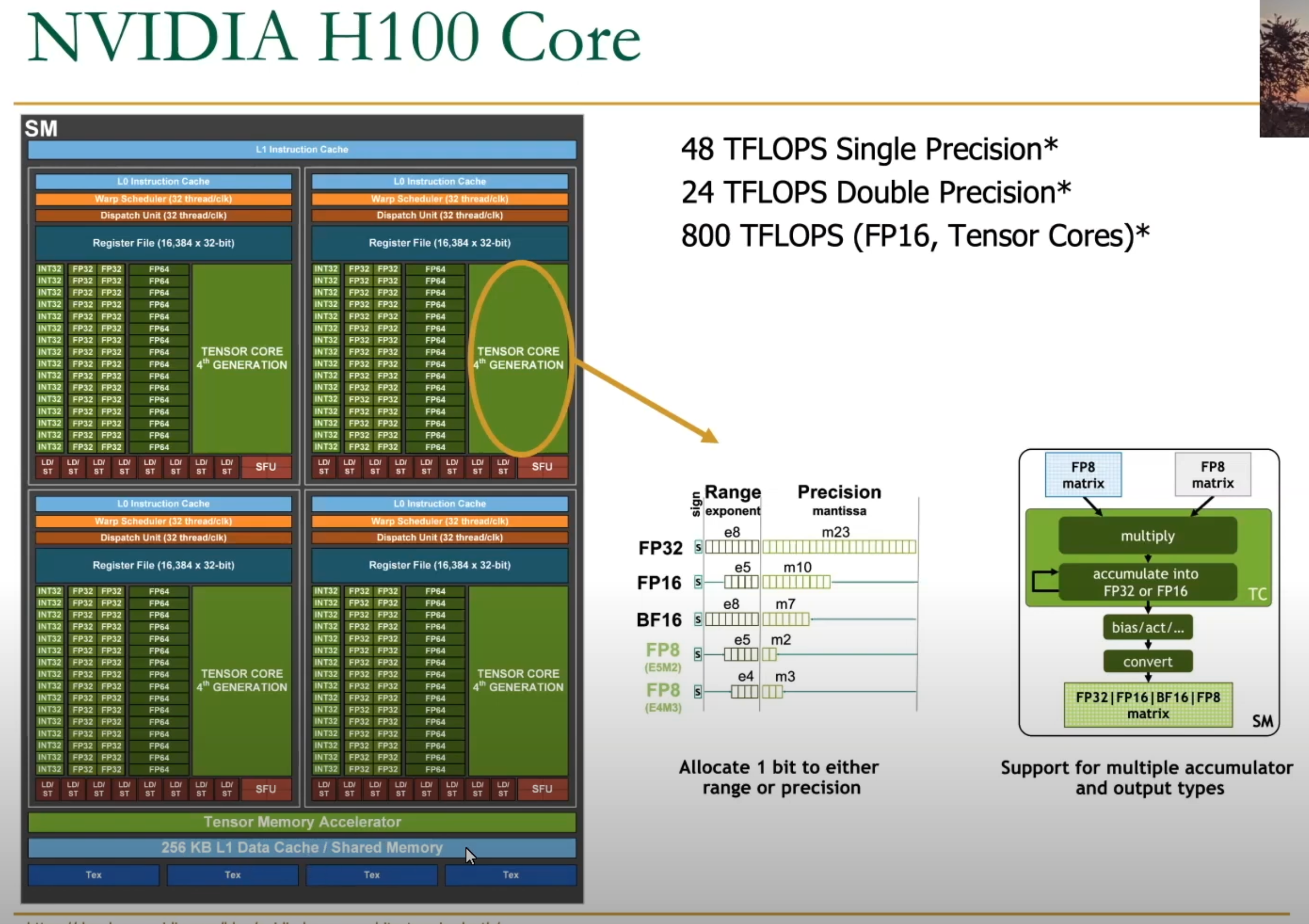
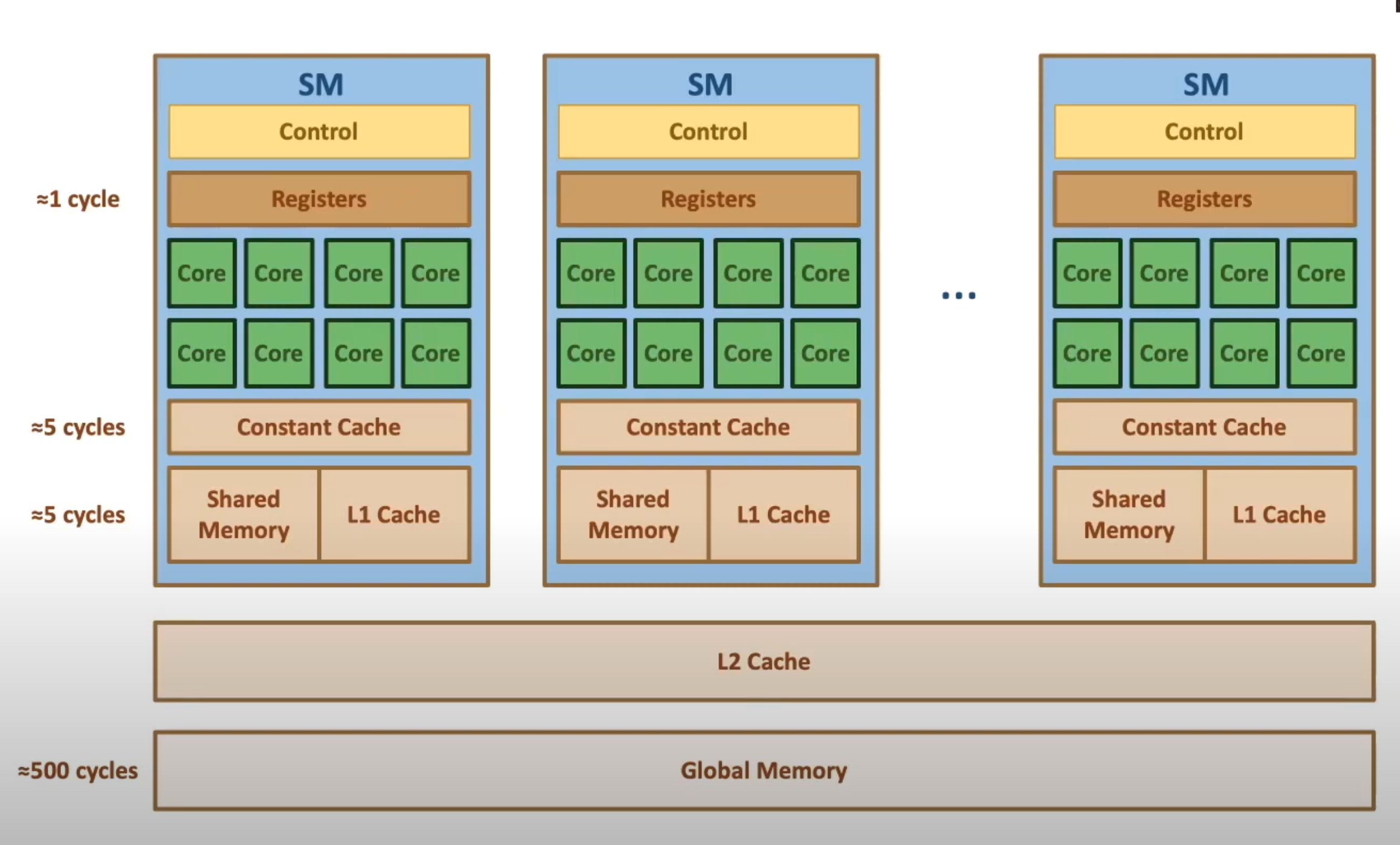
TMA (Tensor Memory Accelerator) - reduces addressing overhead
Distributed Shared Memory