Transformers
- A Mathematical Framework for Transformer Circuits
- Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level (Post 1) — AI Alignment Forum
- An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers v2 — AI Alignment Forum
- Toy Models of Superposition
- Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
- Softmax Linear Units
- Concrete Steps to Get Started in Transformer Mechanistic Interpretability — Neel Nanda
- The Transformer Family Version 2.0 | Lil’Log
- Amazing series from 3Blue1Brown:
- Neel Nanda Transformer Series
- [Public, Approved] Intro to Transformers - Google Slides
Types
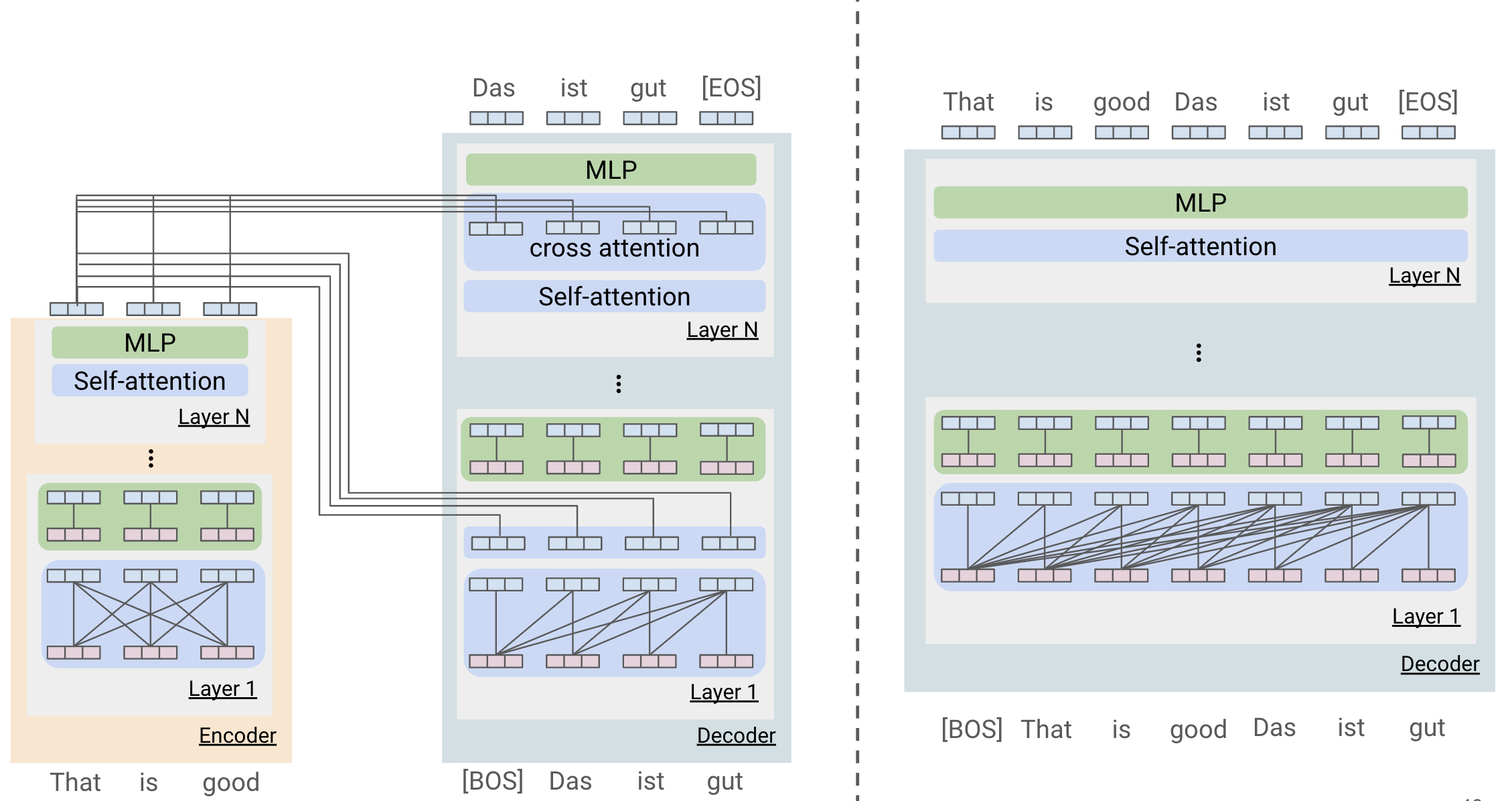
Encoder-Decoder
Attention is all you Need Transformer
T5
Decoder
GPT
Why decoder only beats encoder-decoder (Stanford CS25: V4 I Hyung Won Chung of OpenAI - YouTube):
| Encoder-decoder | Decoder-only | |
|---|---|---|
| Additional cross attention | Separate cross attention | Self-attention serving both roles |
| Parameter sharing | Separate parameters for input and target | Shared parameters |
| Target-to-input attention pattern | Only attends to the last layer of encoder’s output | Within-layer (i.e. layer 1 attends to layer 1) |
| Input attention | Bidirectional | Unidirectional* |
- In generative applications causal attention allows us to cache previous steps since tokens only attend up to their step (KV Cache)
- With encoder models need to recompute full sequence at each step to update previous tokens
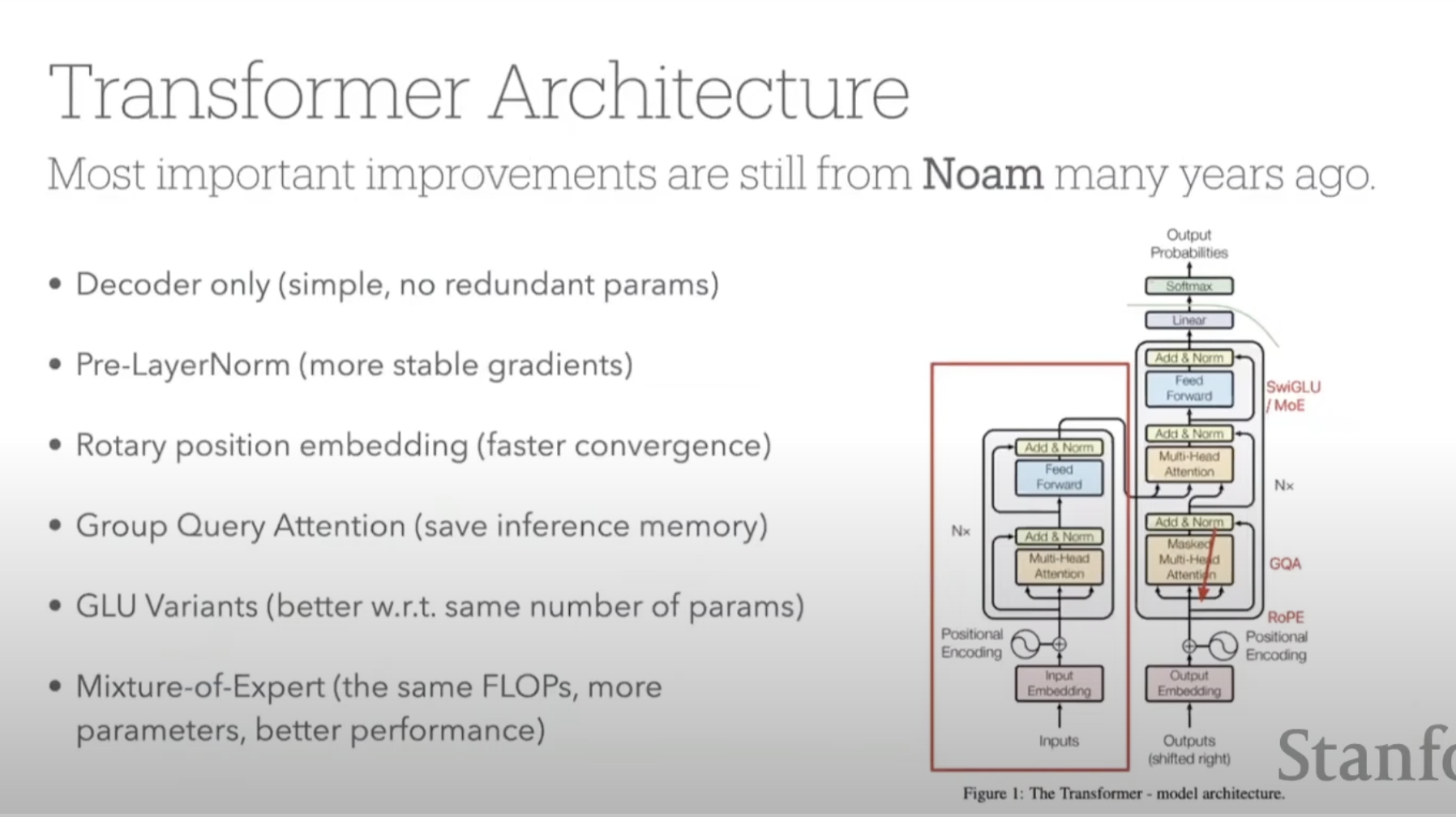
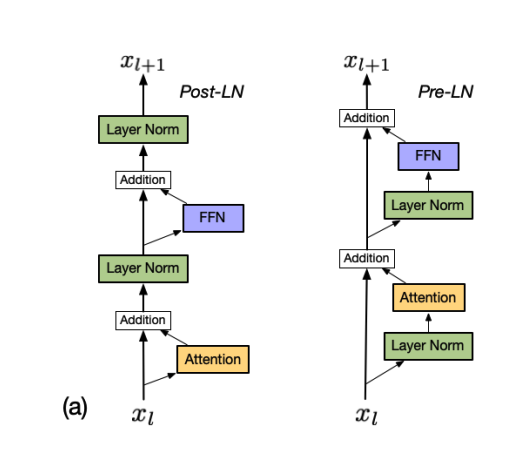
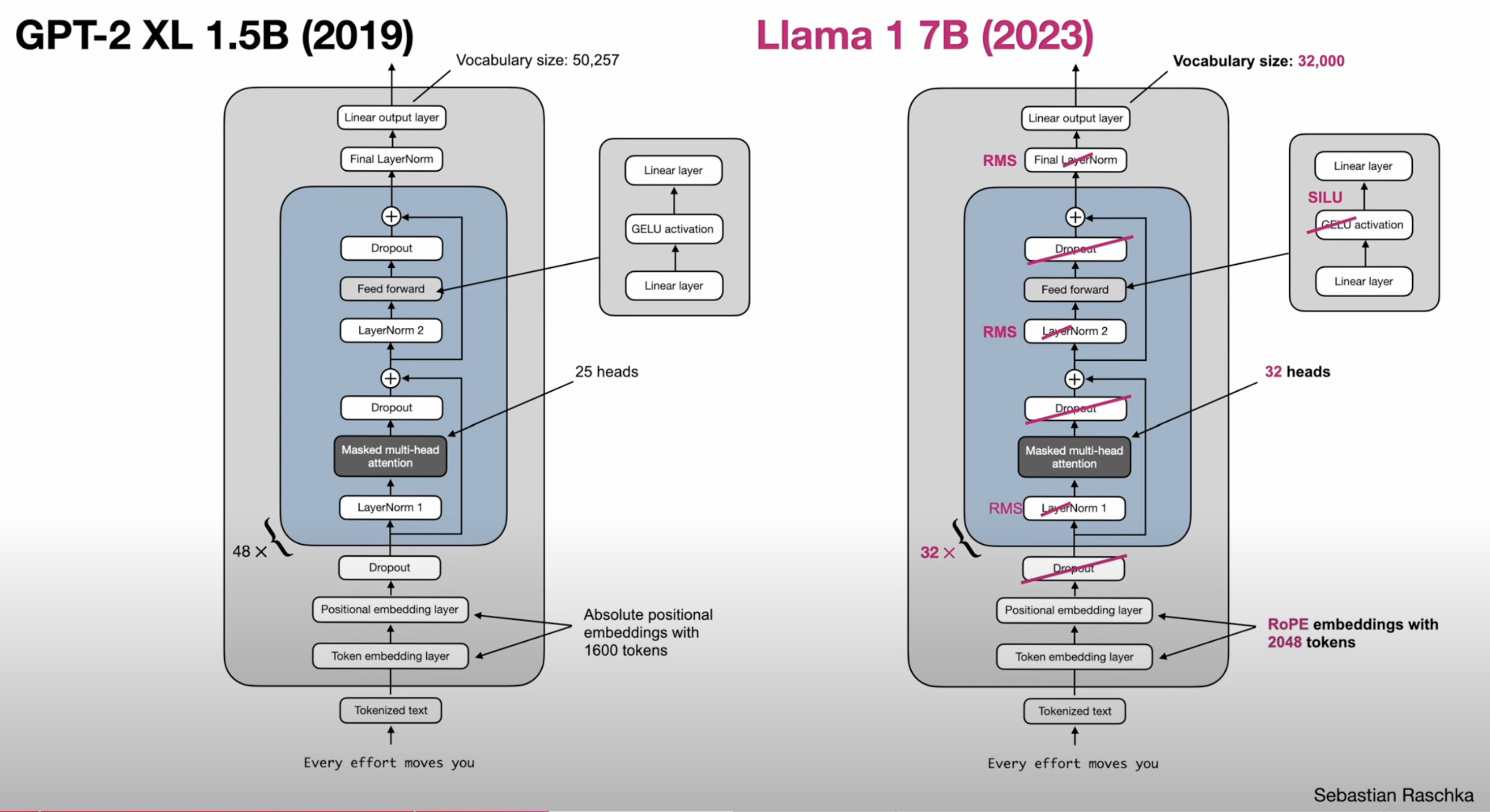
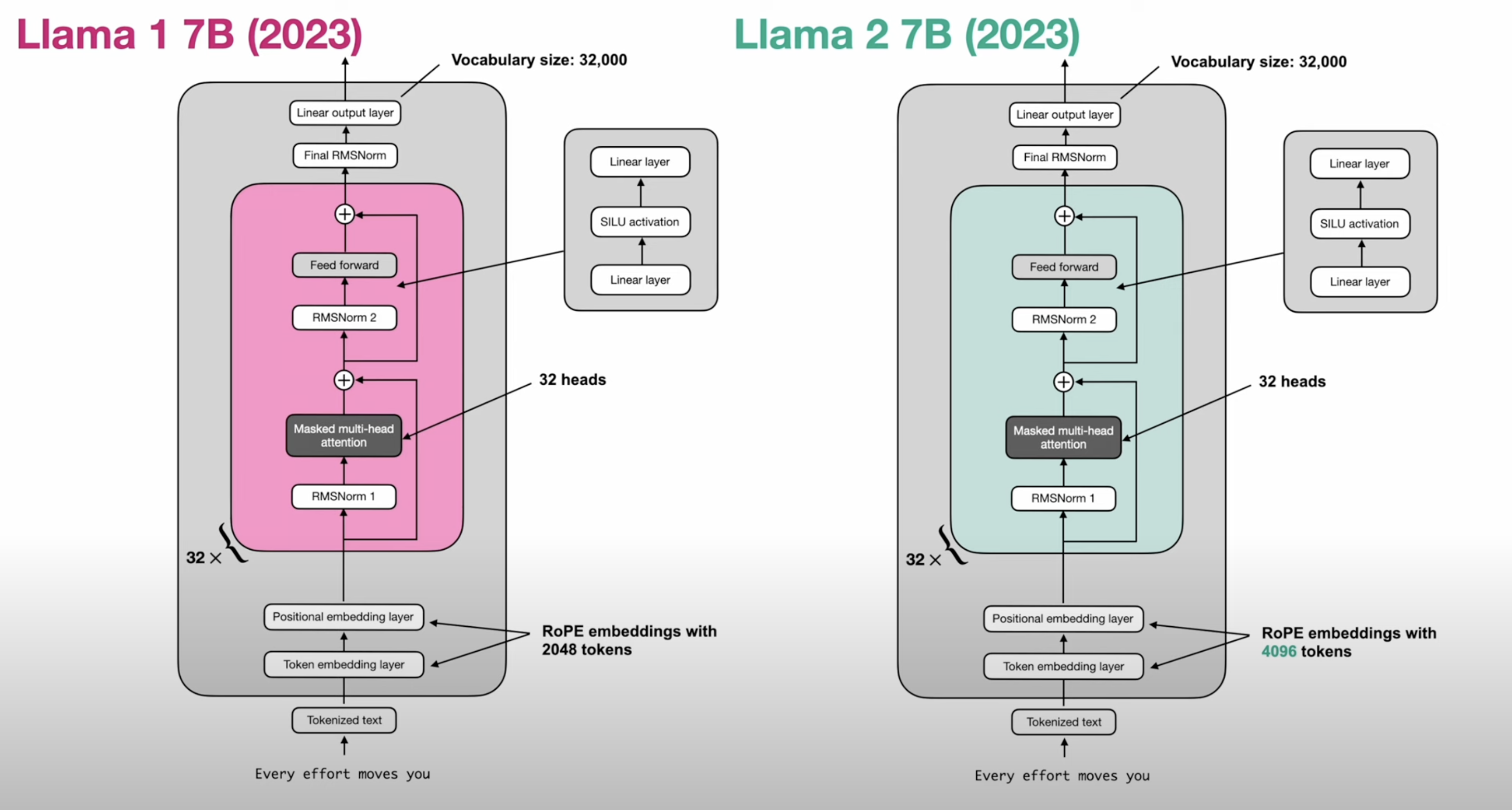
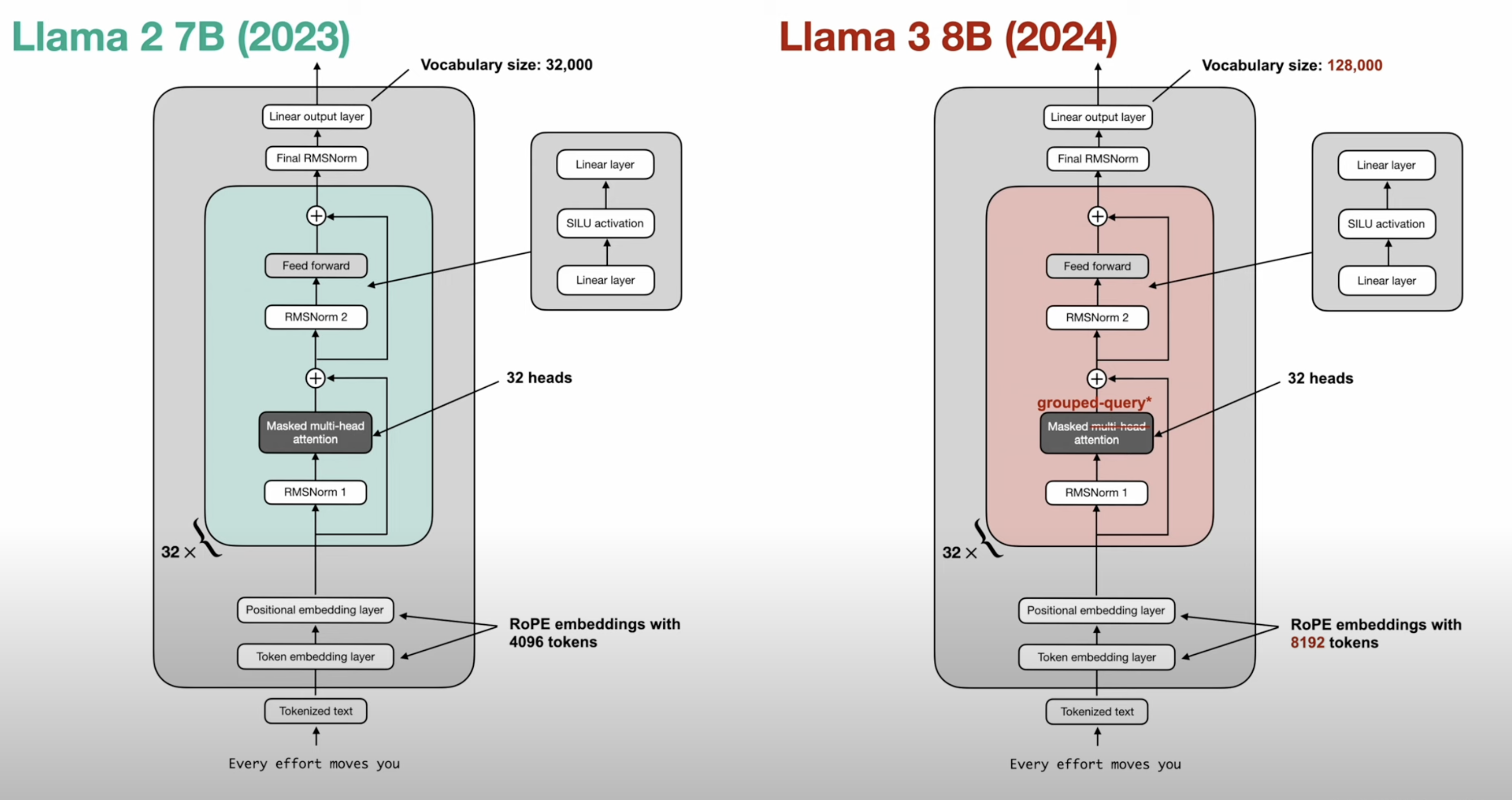
Decoder Improvements
- pre norm (norm before attention)
- RMS norm - cheaper
- RoPE position embeddings
- Grouped Query Attention - Smaller KV cache
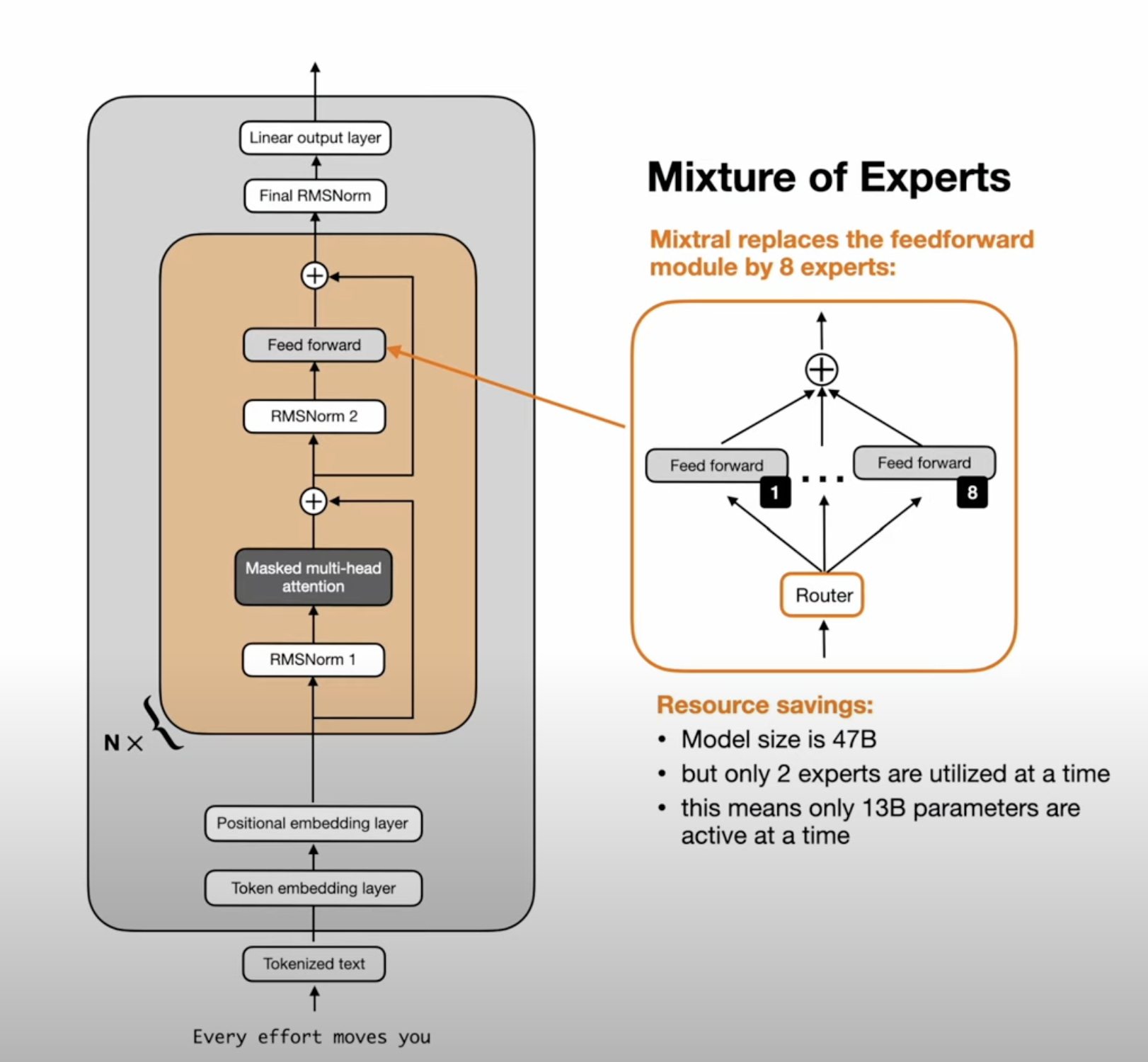
- Mixture of Experts - More Parameters with less Flops
- SwiGLU / other GLU variants
Encoder
BERT
Masking and Next Sentence Prediction Tasks
Class Token vs Pooling
ModernBERT
ViT (MAE)
Transformers and LLMs (Large Language Models)
#ml/nlp/llm
Components
Tokenization
- GitHub - SumanthRH/tokenization: A comprehensive deep dive into the world of tokens
- GitHub - openai/tiktoken: tiktoken is a fast BPE tokeniser for use with OpenAI’s models.
Positional Encoding
RoPE
- Rotary Embeddings: A Relative Revolution | EleutherAI Blog
- [2410.06205] Round and Round We Go! What makes Rotary Positional Encodings useful?
ALiBi
Learned Positional Encoding
Sinusoidal Positional Encoding
Embedding Tables
Tied Embeddings
Attention
Flash Attention
Grouped Query Attention
Flex Attention
Sliding Window Attention
Normalization
RMS Norm
Why not BatchNorm
Can’t use batchnorm in causal models because it leads to information leakage (since it uses batch level statistics)
QK Norm
Residual
Residual Stream
Feed Forward
SwiGLU
Activation Functions
ReLU^2
Classifier
MoE - Mixture of Experts
Tricks
Speculative Decoding
KV Cache
Context Length
Transformer Variants
nGPT - Normalized Transformer
TokenFormer
2024-11-03 - TokenFormer - RETHINKING TRANSFORMER SCAL-ING WITH TOKENIZED MODEL PARAMETERS
Sigmoid Attention
Diff Transformer
Block Transformer
YOCO - You Only Cache Once
Topics and Trends
- LLM Worksheet - Google Sheets
- GitHub - lm-sys/FastChat: The release repo for “Vicuna: An Open Chatbot Impressing GPT-4”
- GitHub - kernelmachine/cbtm: Code repository for the c-BTM paper
”Reasoning” / Test Time Compute
Test Time Compute, LLM Reasoning, Inference Time Scaling
Multimodal Transformers
Vision Language Models
Vision Language Action Models
”Omni” Models
Chat
- GitHub - imoneoi/openchat: OpenChat: Advancing Open-source Language Models with Imperfect Data
- LangChain
Alignment
Instruction Tuning
- GitHub - huggingface/alignment-handbook: Robust recipes for to align language models with human and AI preferences
- GitHub - allenai/open-instruct
RLHF
DPO
Training
Fine Tuning
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions
- GitHub - unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory
Parameter Efficient Fine Tuning (PEFT)
LoRA - Low Rank Adaptation
Transformer^2
Distillation / Pruning / Compression
Inference
Decoder Transformer Inference (LLM Serving)
GGML / LLAMA.CPP
Introduction to ggml llama.cpp guide - Running LLMs locally, on any hardware, from scratch ::
Open Models
Serving
Quantization
- GitHub - PanQiWei/AutoGPTQ: An easy-to-use LLMs quantization package with user-friendly apis, based on GPTQ algorithm.
- GitHub - IST-DASLab/gptq: Code for the ICLR 2023 paper “GPTQ: Accurate Post-training Quantization of Generative Pretrained Transformers”.
Visualization
Sampling and Decoding
Inference Benchmarks
Evaluation
Evaluate LLMs and RAG a practical example using Langchain and Hugging Face
Applications
Text to SQL
Links
Articles
-
Transformer Walkthrough: A walkthrough of transformer architecture code (2022 - Riedl)
-
https://github.com/cmhungsteve/Awesome-Transformer-Attention
Lectures
Code
- xformers: Hackable and optimized Transformers building blocks, supporting a composable construction.
- GitHub - lucidrains/x-transformers: A simple but complete full-attention transformer with a set of promising experimental features from various papers
- GitHub - explosion/curated-transformers: 🤖 A PyTorch library of curated Transformer models and their composable components