Speech Recognition
Transducers - RNN-T
Separate source encoder for input sequence and “predictor” model that only predicts next token in output space (LLM), with a “Joiner” module that takes the encoder and predictor outputs and combines them to predict the next output.
-
good for streaming
-
+ can pretrain the predictor in self supervised fashion on next token prediction
-
Sequence-to-sequence learning with Transducers - Loren Lugosch
-
In Depth Explaination Of RNN-T based Automatic Speech Recognition Systems (ASR) - YouTube
HuBERT
CTC
Decoding
Greedy
Beam Search
Conformer
Whisper
Mamba
TTS - Text to Speech
- TTS Arena - a Hugging Face Space by TTS-AGI
- GitHub - fishaudio/fish-speech: SOTA Open Source TTS
- GitHub - edwko/OuteTTS: Interface for OuteTTS models.
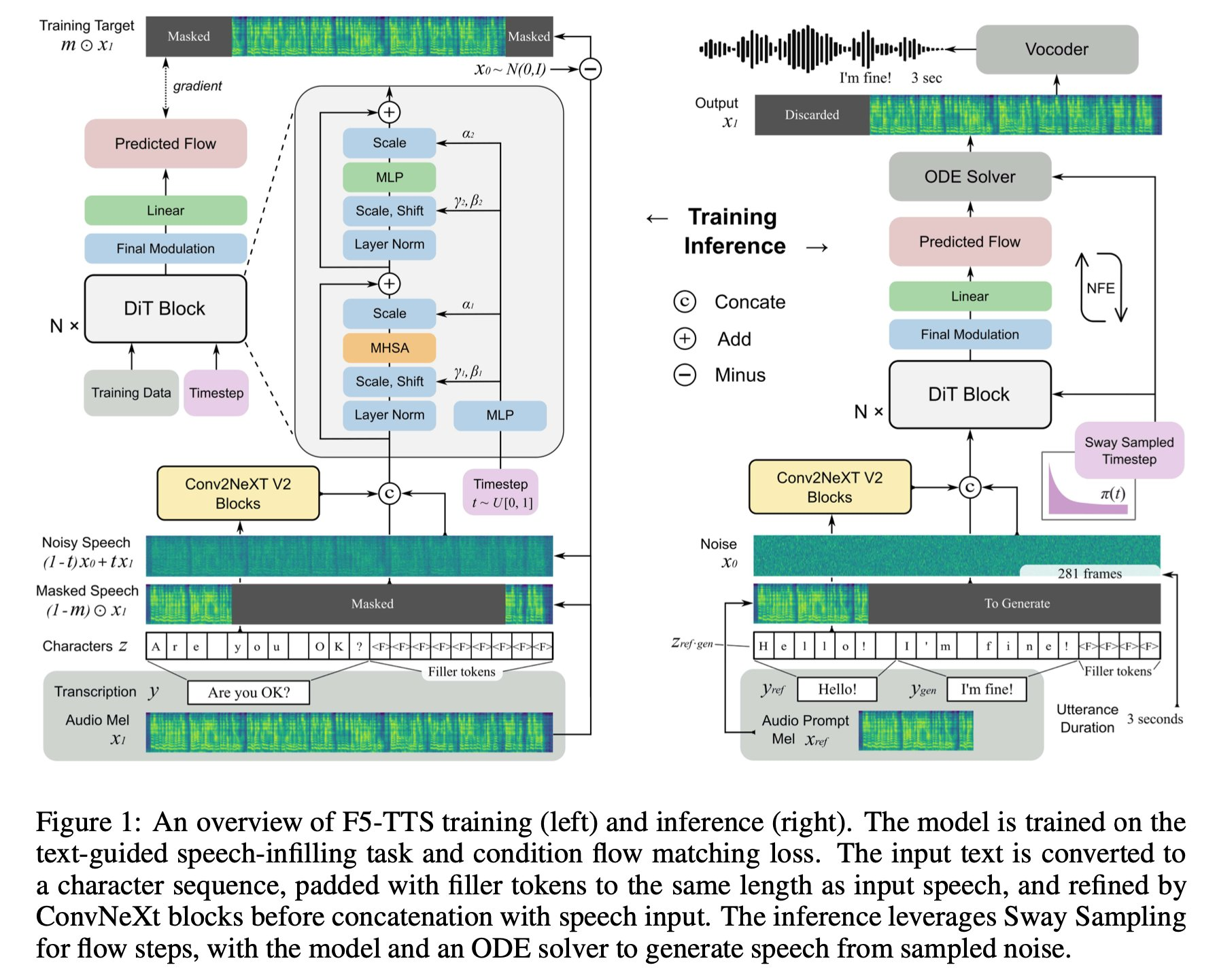
F5-TTS
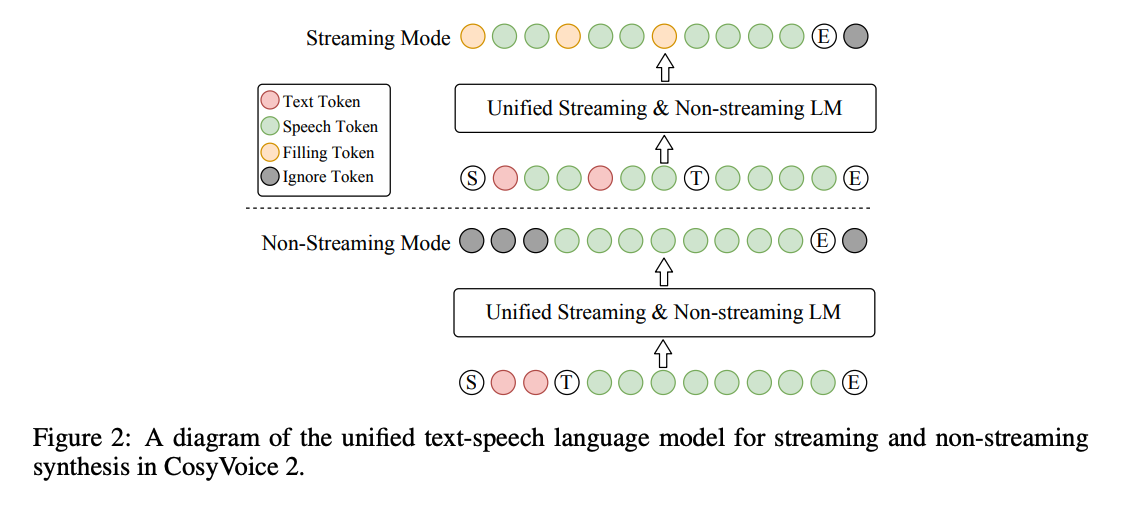
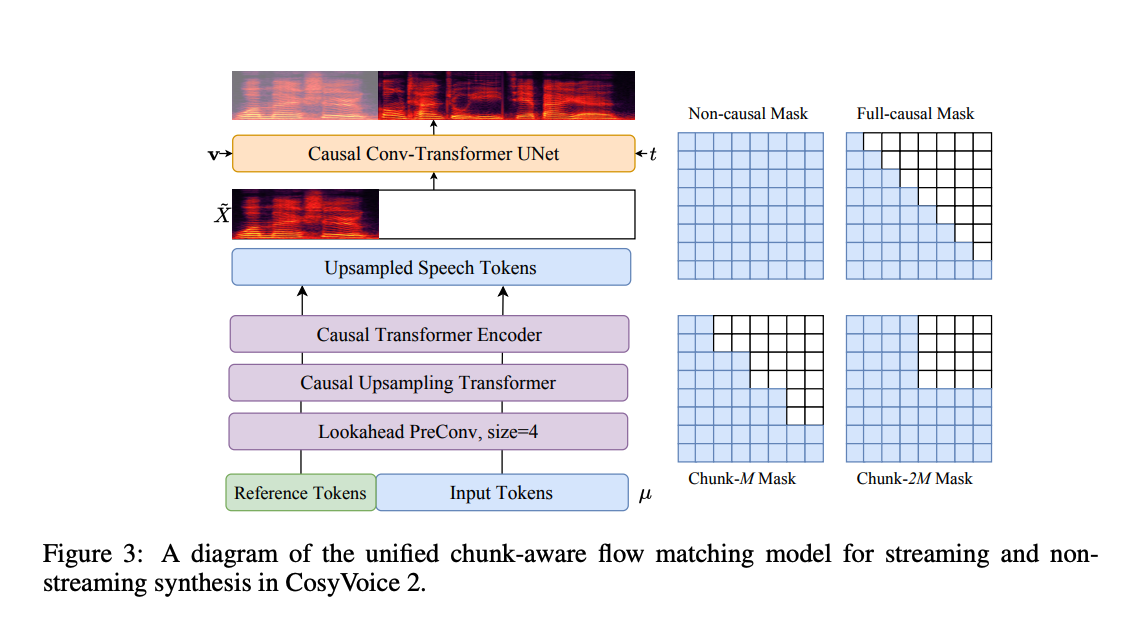
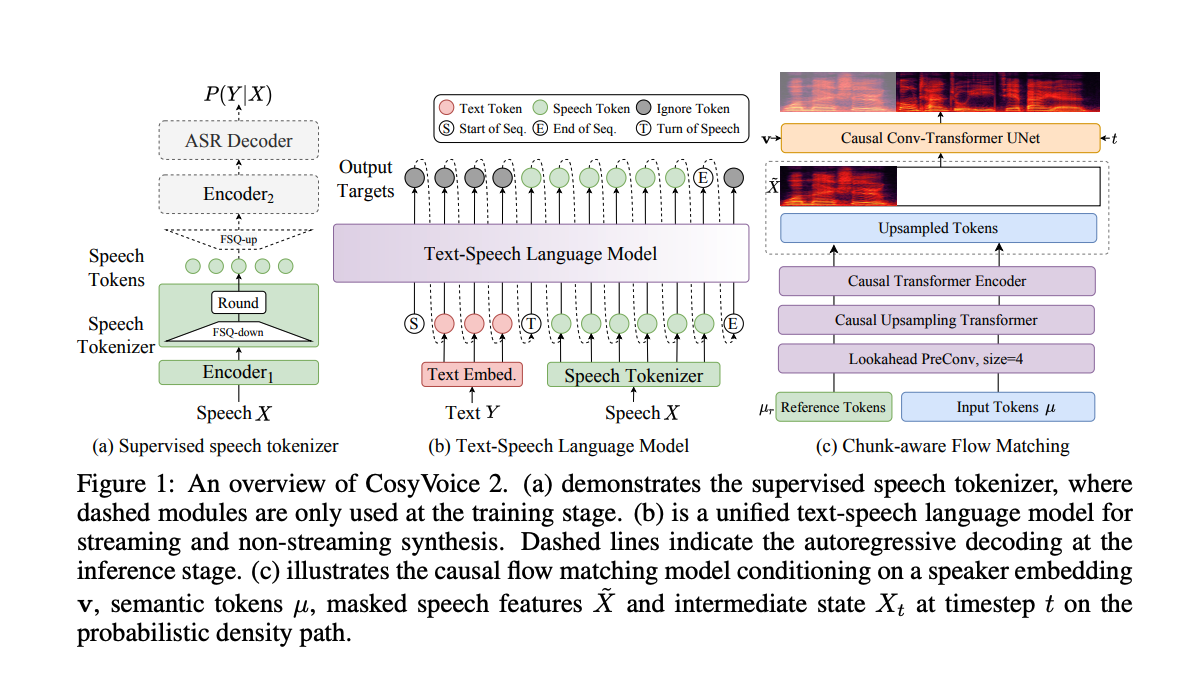
CosyVoice 2
End to End Multimodal Speech to Speech
Spirit LM
- GitHub - facebookresearch/spiritlm: Inference code for the paper “Spirit-LM Interleaved Spoken and Written Language Model”.
- SpiRit-LM, an Interleaved Spoken and Written Language Model | Multimodal Weekly 47 - YouTube