2024-09-02
Papers
- [2404.16710] LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding #transformers
- [2405.04434] DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
-
- [2409.02060] OLMoE: Open Mixture-of-Experts Language Models
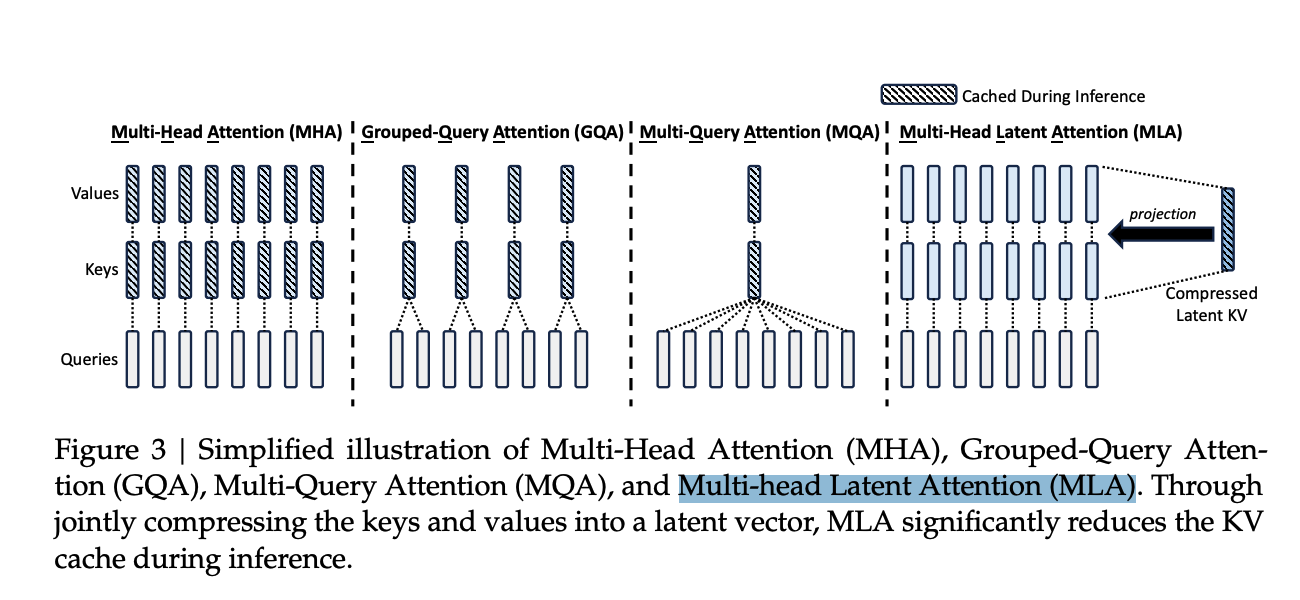
Models
-
OLMoE - 1B Mixture of Experts #moe
- [2409.02060] OLMoE: Open Mixture-of-Experts Language Models
- Niklas Muennighoff on X: “Releasing OLMoE - the first good Mixture-of-Experts LLM that’s 100% open-source - 1B active, 7B total params for 5T tokens - Best small LLM & matches more costly ones like Gemma, Llama - Open Model/Data/Code/Logs + lots of analysis & experiments 📜https://t.co/Vpac2q90CS 🧵1/9 https://t.co/YOMV5t2Td1” / X
- - Niklas Muennighoff on X: “OLMoE Efficiency Thanks to Mixture-of-Experts, better data & hyperparams, OLMoE is much more efficient than OLMo 7B: - >4x less training FLOPs - >5x less params used per forward pass i.e. cheaper training + cheaper inference! 🧵3/9 https://t.co/as9CNMTw9j” / X
-
Meet Yi-Coder: A Small but Mighty LLM for Code - 01.AI Blog #code-model
-
Reflection 70B
- Matt Shumer on X: “The technique that drives Reflection 70B is simple, but very powerful. Current LLMs have a tendency to hallucinate, and can’t recognize when they do so. Reflection-Tuning enables LLMs to recognize their mistakes, and then correct them before committing to an answer. https://t.co/pW78iXSwwb” / X
- mattshumer/Reflection-70B · Hugging Face
-
Salesforce xLAM
Videos
- Lecture 28: Liger Kernel - Efficient Triton Kernels for LLM Training - YouTube #triton
- int64 addressing slower than int32, need to cast to int64 for large tensors
- Cohere For AI - Community Talks: Mostafa Elhoushi & Akshat Shrivastava - YouTube
Dev
- Production-ready Python Docker Containers with uv #python #uv #docker
- CUDA-Free Inference for LLMs | PyTorch #pytorch
- SGLang v0.3 Release: 7x Faster DeepSeek MLA, 1.5x Faster torch.compile, Multi-Image/Video LLaVA-OneVision | LMSYS Org
- Advanced Python: Achieving High Performance with Code Generation | by Yonatan Zunger | Medium
Random
- Ilya Sutskever’s SSI Inc raises $1B | Hacker News
- Dylan Freedman on X: “The new Qwen2-VL-7B Instruct model gets 100% accuracy extracting text from this handwritten document. This is the first open weights model (Apache 2.0) that I’ve seen OCR this accurately. (Thank you @fdaudens for the tip!) https://t.co/AB9r3bKDF0 https://t.co/nAEY7cp1w8” / X
- Fetching Title#xsta