2024-10-14
Models
- Introducing Play 3.0 Mini - A Lightweight, Reliable And Cost-efficient Multilingual Text-to-Speech Model
- 🍓 Ichigo: Llama learns to talk - Homebrew
- - Zyphra on X: “Today, in collaboration with @NvidiaAI, we bring you Zamba2-7B – a hybrid-SSM model that outperforms Mistral, Gemma, Llama3 & other leading models in both quality and speed. Zamba2-7B is the leading model for ≤8B weight class. 👇See more in the thread below👇 https://t.co/v1PttlaZq5” / X
- nvidia/Llama-3.1-Nemotron-70B-Instruct · Hugging Face
- deepseek-ai/Janus-1.3B · Hugging Face
Papers
- Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
- [2410.10819] DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
- [2410.02367] SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
- [2410.06511v1] TorchTitan: One-stop PyTorch native solution for production ready LLM pre-training
- [2410.10630] Thinking LLMs: General Instruction Following with Thought Generation
- Sana - Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer
- [2410.07815] Simple ReFlow: Improved Techniques for Fast Flow Models
- [2410.10733v1] Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
Code
- GitHub - AI-Hypercomputer/maxtext: A simple, performant and scalable Jax LLM!
- GitHub - mit-han-lab/efficientvit: Efficient vision foundation models for high-resolution generation and perception.
Articles
- Linearizing LLMs with LoLCATs
- Decentralized Training of Deep Learning Models
- INTELLECT–1: Launching the First Decentralized Training of a 10B Parameter Model
- Bug Fixes in LLM Training - Gradient Accumulation
Videos
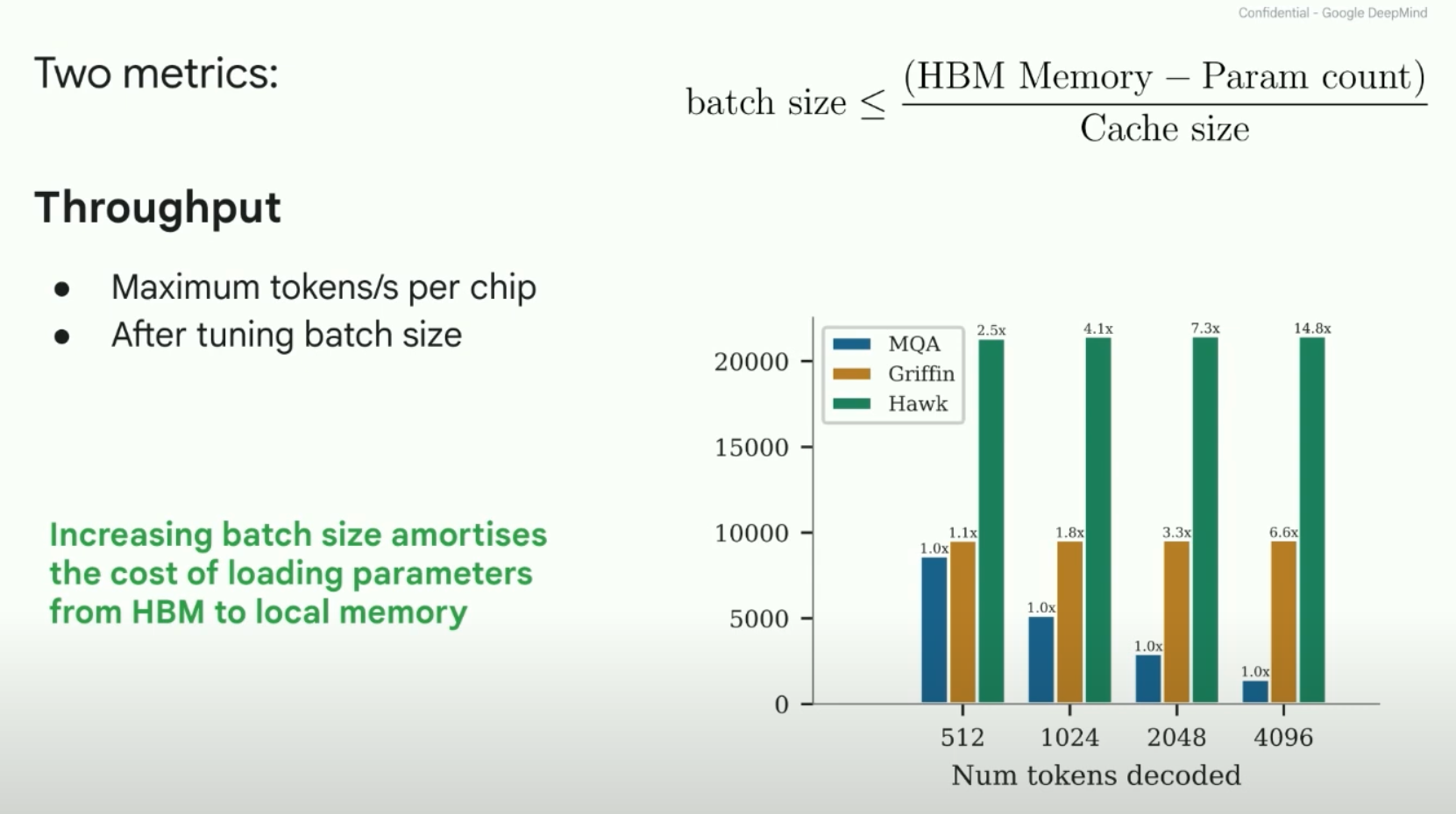
- On the Tradeoffs of State Space Models - YouTube
- Sam Smith - How to train an LLM - IPAM at UCLA - YouTube
- Keynote: Yann LeCun, “Human-Level AI” - YouTube
Other
- [ ]
Tweets
Notes
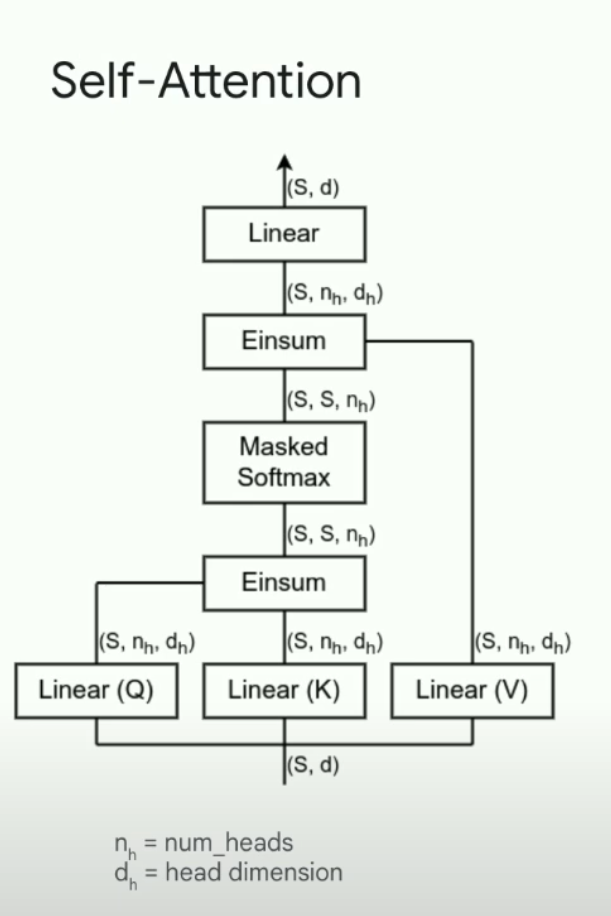
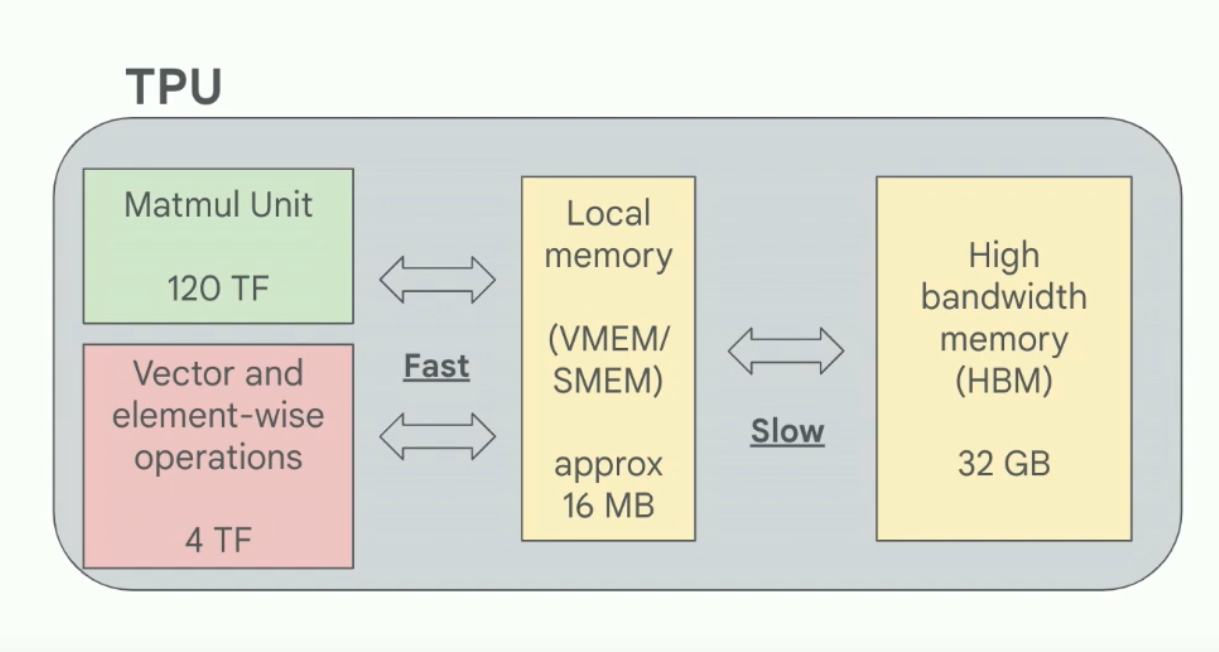
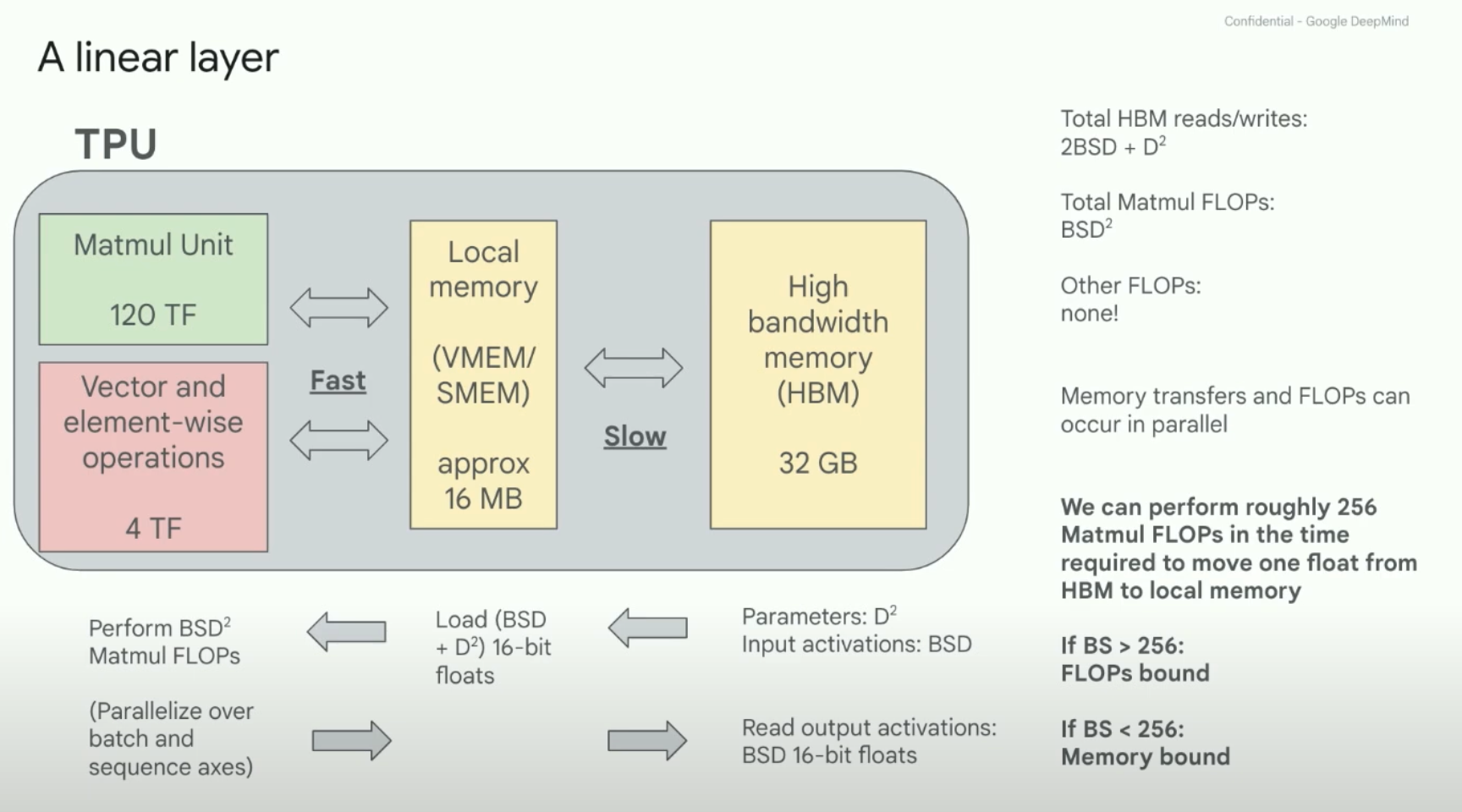
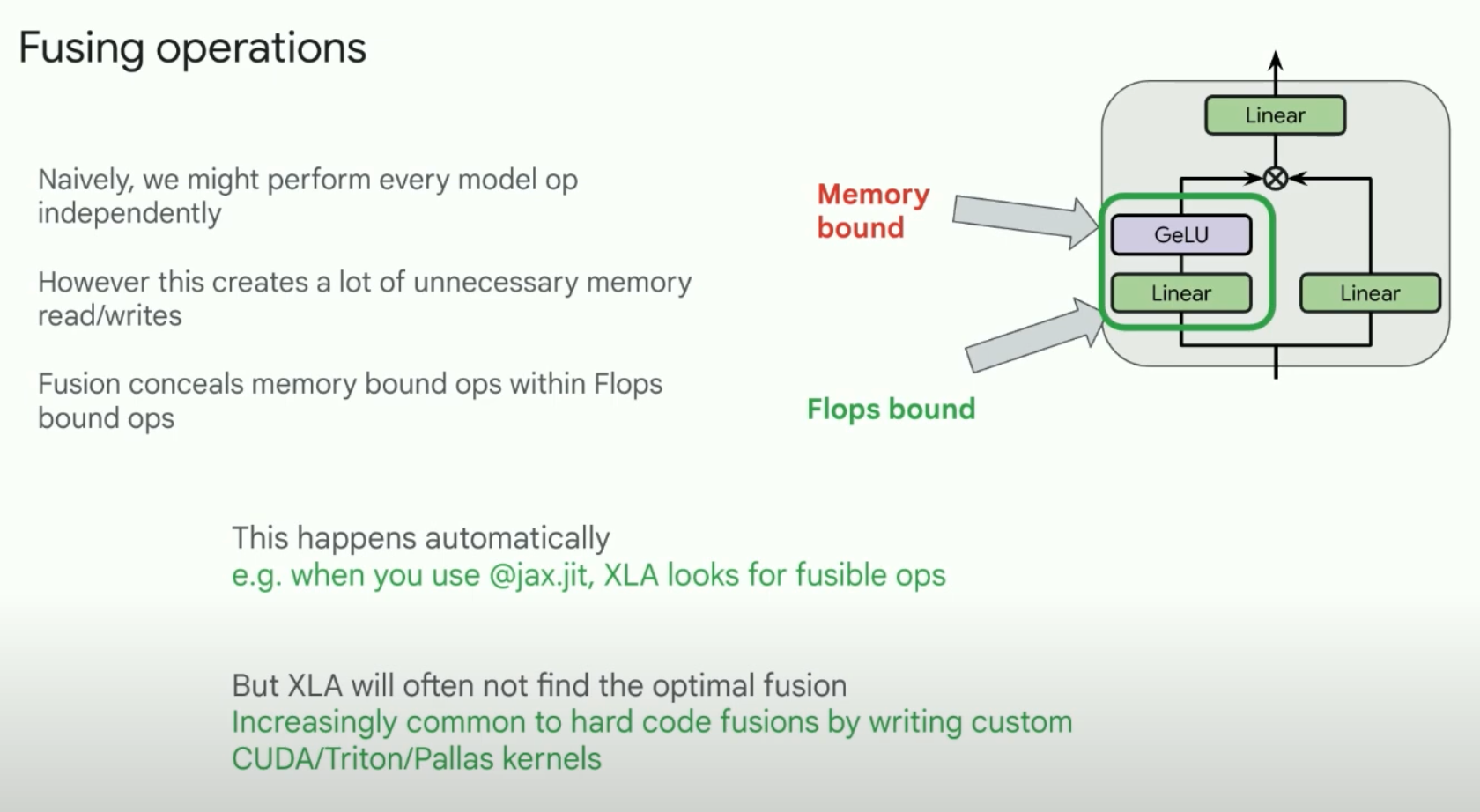
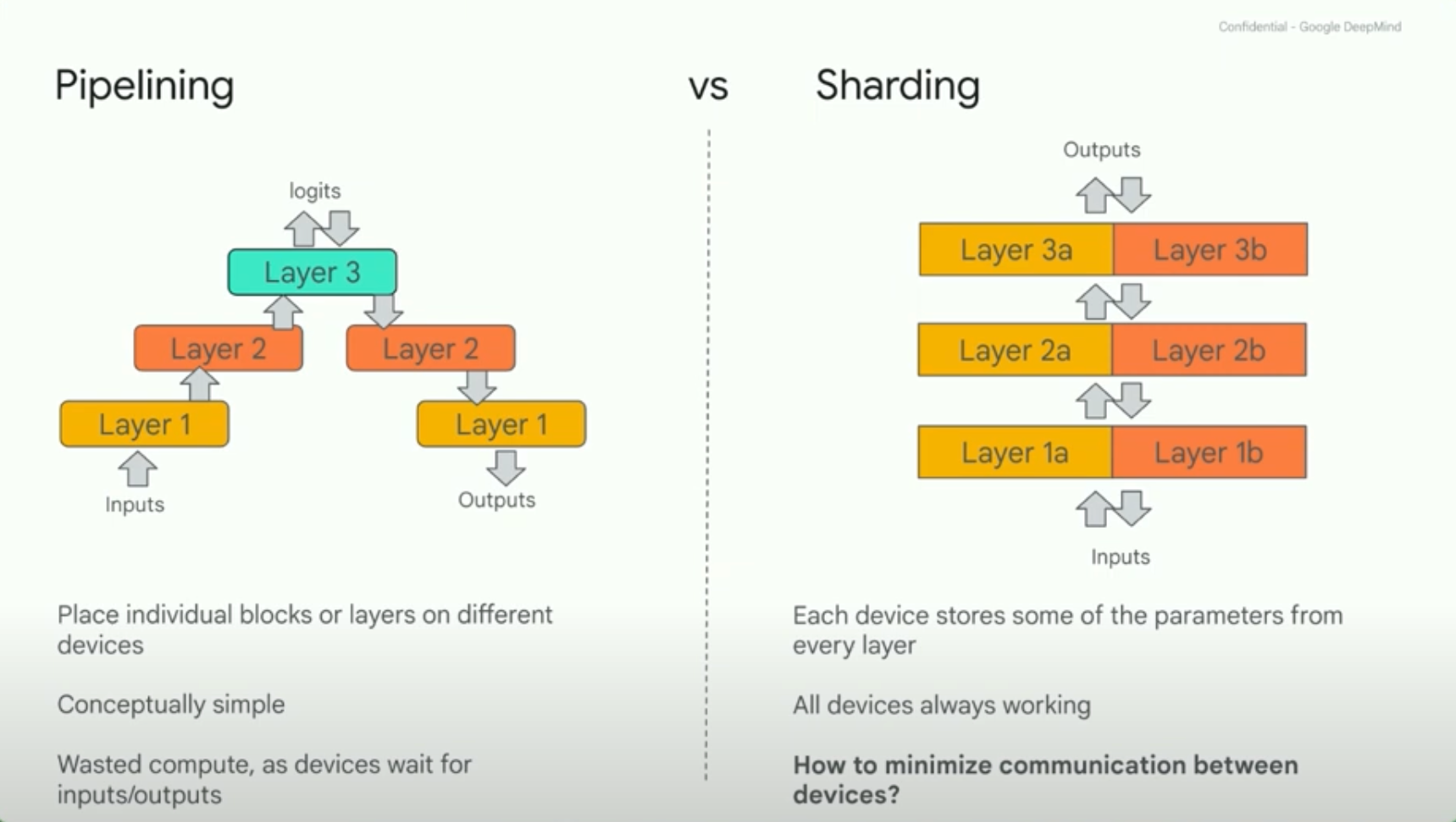
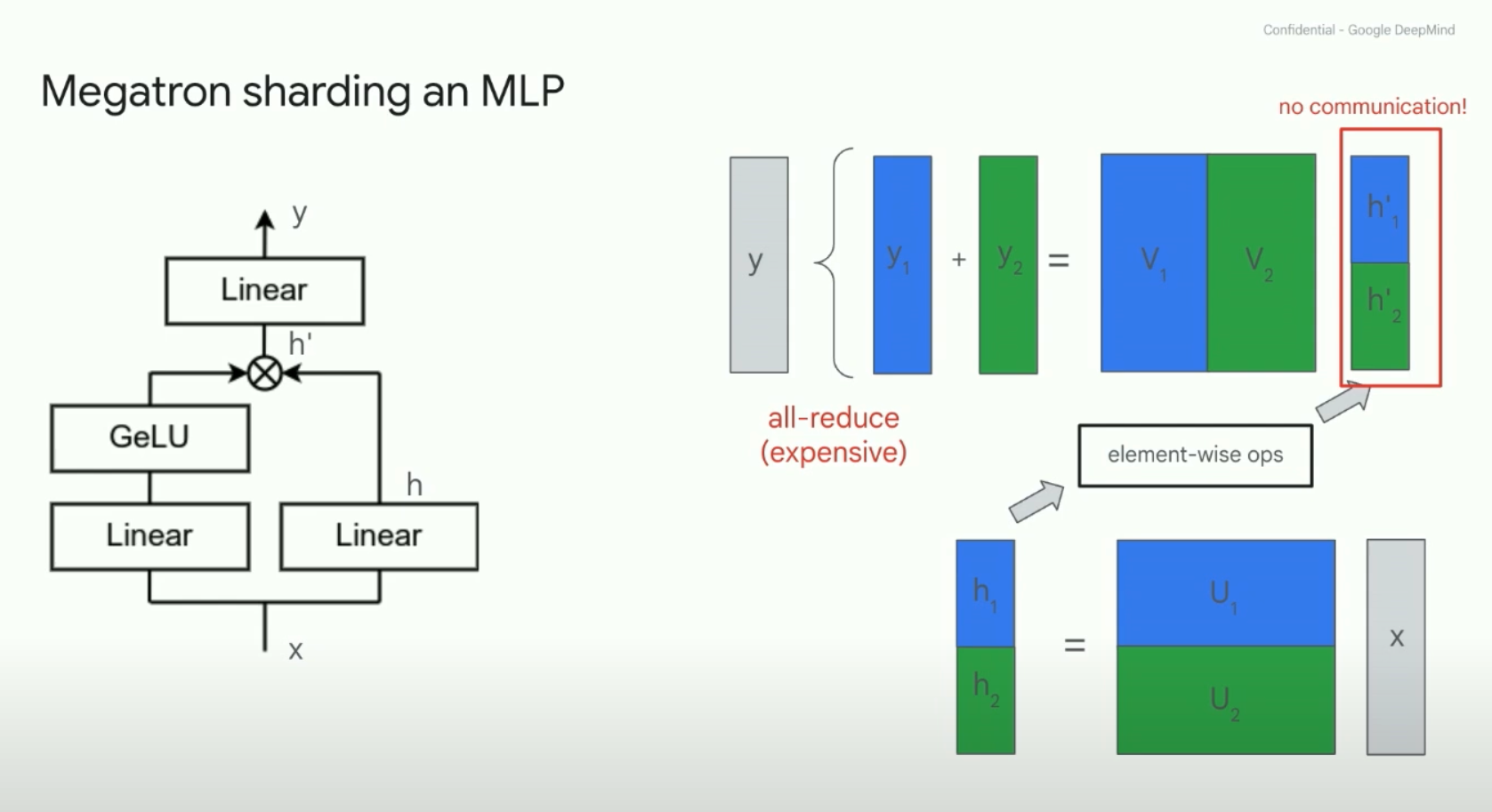
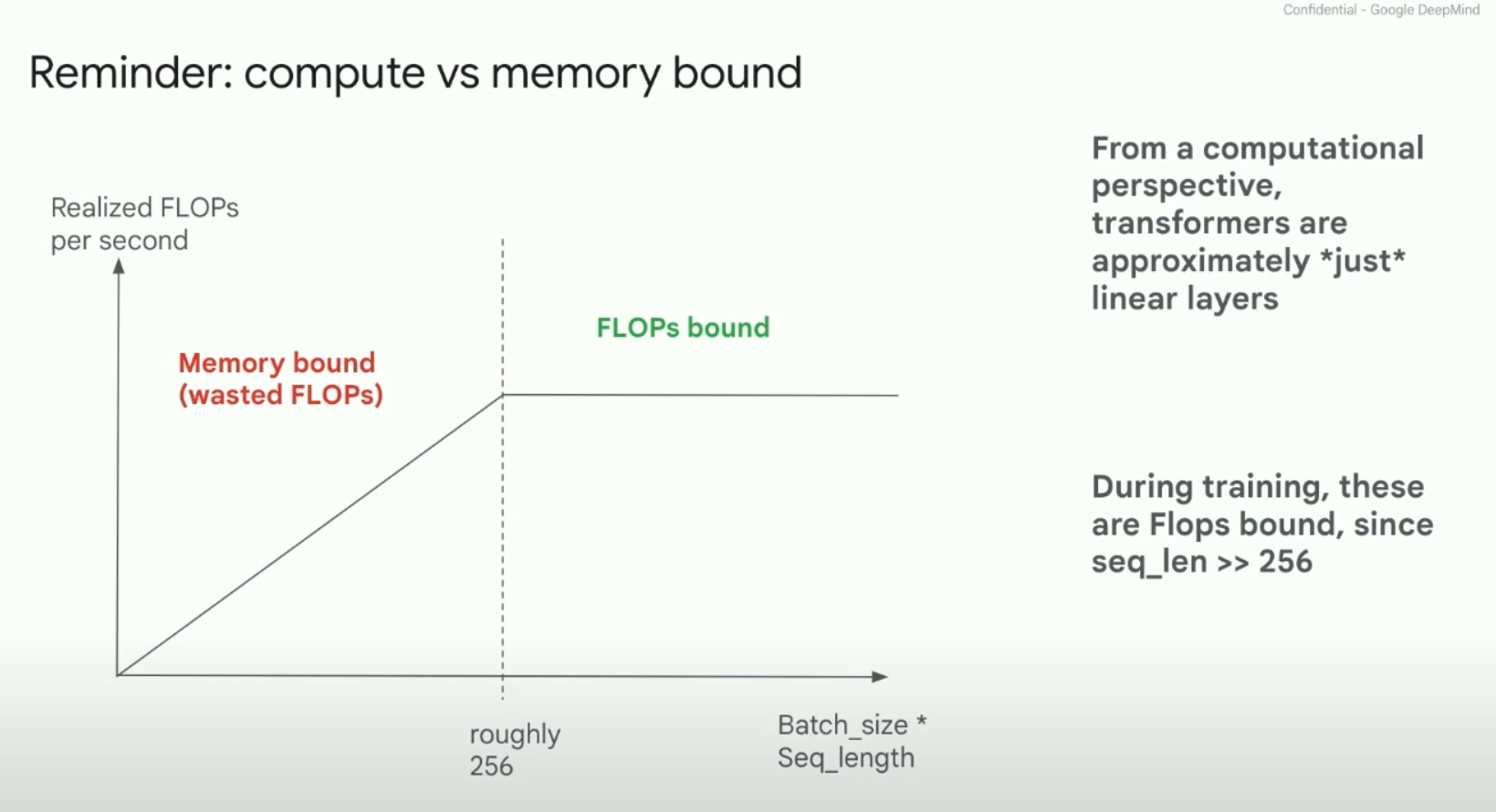
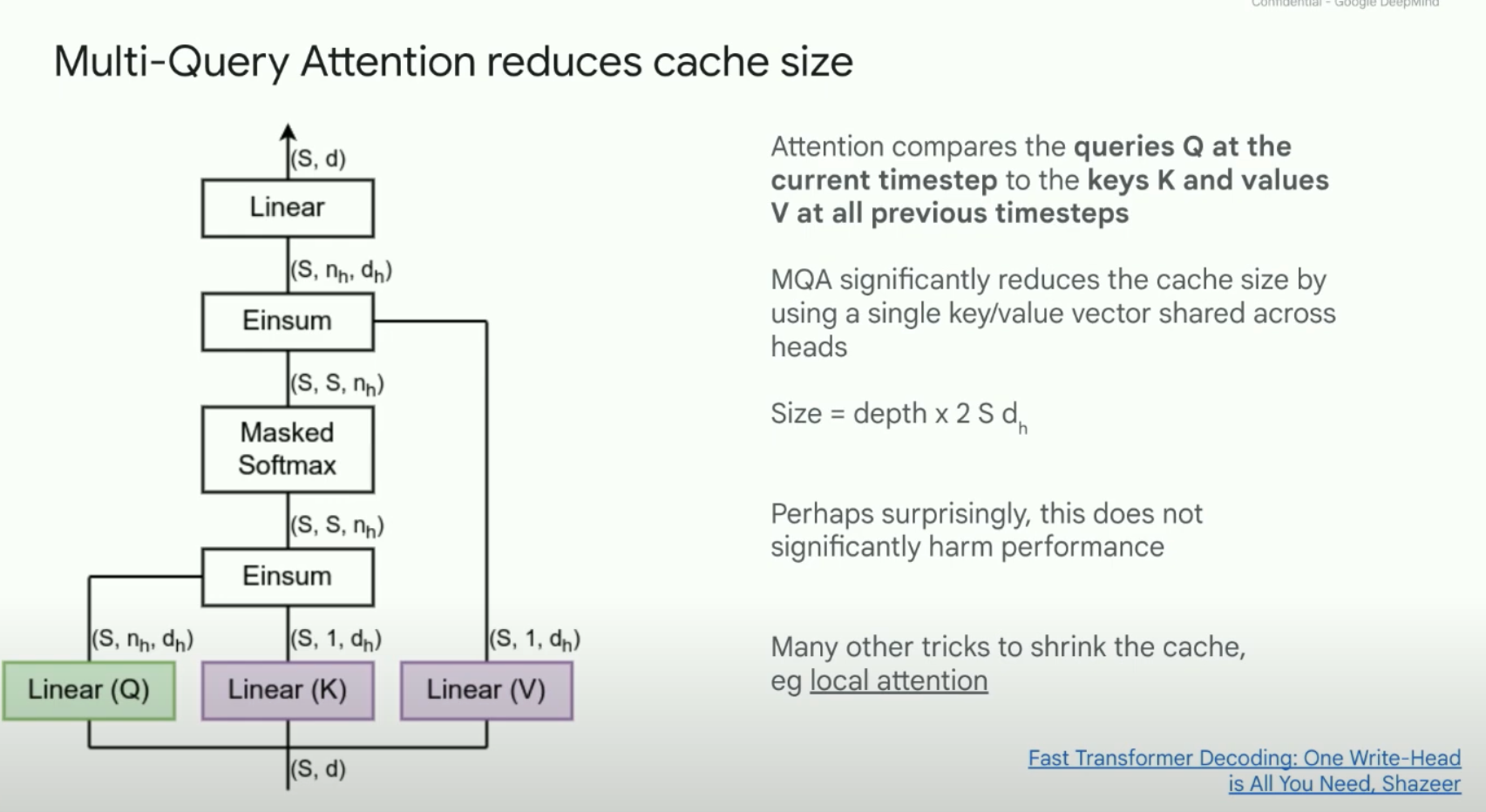
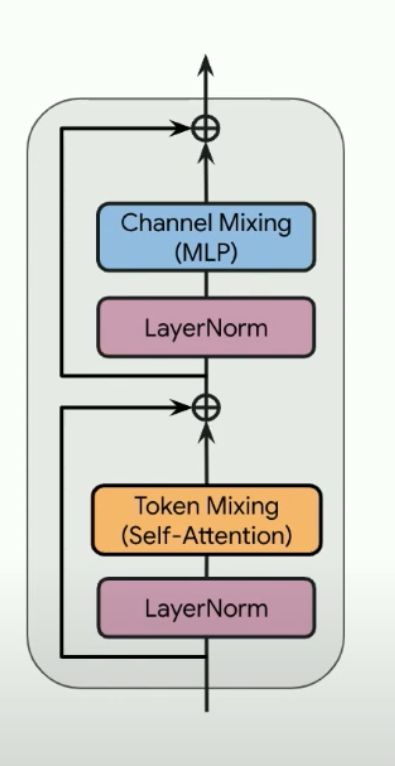
Sam Smith - How to train an LLM
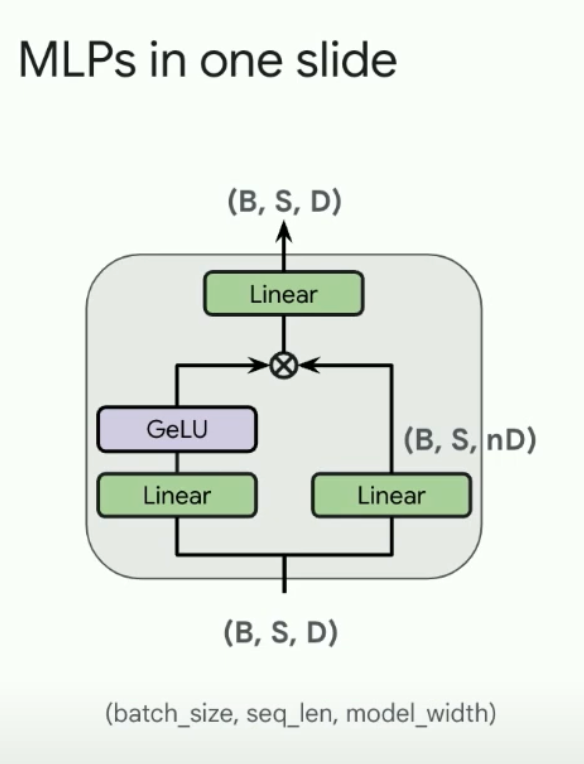
Gated MLPs